
nao
nao — IDE для аналитиков и инженеров данных. Помогает писать SQL, Python, YAML с учетом схем данных, проверяет качество и визуализирует изменения.
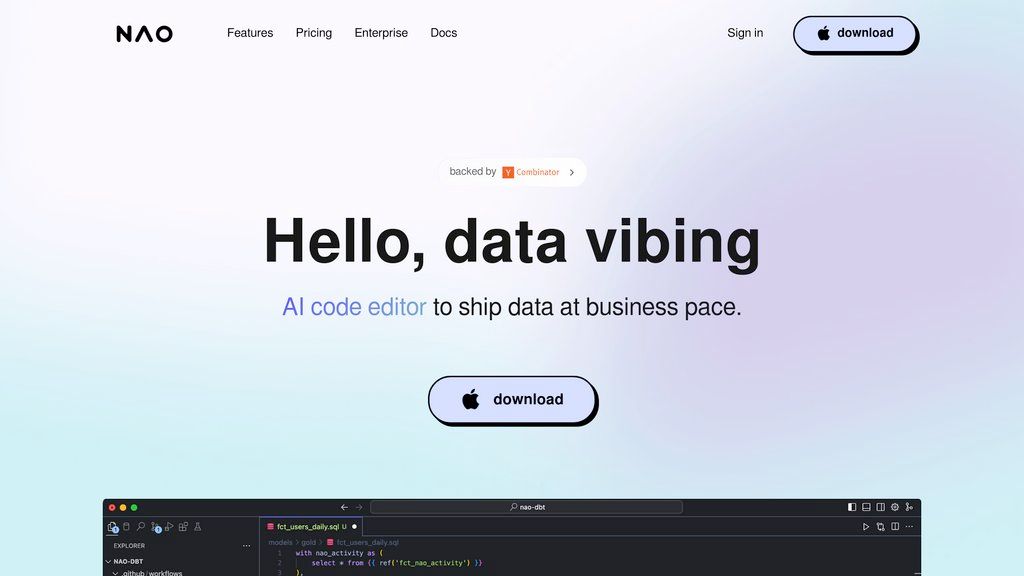
Обзор nao
nao — это специализированная среда разработки (IDE) для специалистов по данным, построенная на базе VS Code. Она интегрируется напрямую с популярными хранилищами данных, такими как BigQuery, Snowflake и Postgres. Ключевая особенность — интеллектуальный помощник (copilot), который анализирует схемы данных и существующий код, позволяя писать более точные SQL, Python и YAML запросы. Инструмент решает проблему ошибок и низкой скорости разработки в командах, работающих с большими объемами данных. Предоставляя предварительный просмотр изменений данных (data diff), автоматизированные проверки качества и анализ влияния на нижестоящие процессы (lineage impact analysis), nao помогает снизить количество багов, ускорить выпуск новых моделей данных и поддерживать их целостность.
Главные функции
Прямая интеграция с хранилищами
Подключайтесь к BigQuery, Snowflake и Postgres для получения актуального контекста схемы и автодополнения кода.
Код с учетом схем
Генерируйте SQL, Python и YAML, который автоматически адаптируется к вашим таблицам и столбцам для повышения точности.
Визуализация изменений данных
Сравнивайте код и его влияние на выходные данные в режиме реального времени, чтобы видеть, как изменения затрагивают датасеты.
Автоматическая проверка качества
Встроенные инструменты для поиска дубликатов, аномалий, сравнения сред и оценки влияния на нижестоящие процессы.
Интеграция с dbt
Полная поддержка dbt-проектов: предпросмотр моделей, трекинг lineage на уровне столбцов, генерация документации и тестов.
Плюсы и минусы
Преимущества
- Ускоряет разработку и снижает количество ошибок благодаря ИИ-помощнику, понимающему схемы данных.
- Обеспечивает целостность данных за счет встроенных проверок качества и анализа влияния изменений.
- Упрощает работу с dbt-проектами непосредственно в IDE.
Недостатки
- Эффективность ИИ-помощника зависит от качества и полноты предоставленных схем данных.
- Требует наличия собственных хранилищ данных (BigQuery, Snowflake, Postgres) для полной функциональности.
- Интеграция с dbt предполагает знакомство пользователя с этим фреймворком.
Для кого и как использовать?
Data Analyst
Писать более сложные SQL-запросы для анализа данных, быстро проверять изменения перед применением и получать автодополнение с учетом всех таблиц и колонок.
Data Engineer
Разрабатывать и поддерживать ETL/ELT процессы, автоматизировать проверки качества данных, анализировать влияние изменений в коде на downstream-системы и генерировать документацию для dbt-моделей.
ML Engineer
Создавать Python-скрипты для предобработки данных, используя автодополнение и проверки кода, которые учитывают структуру целевых датасетов.
Частые вопросы
Похожие нейросети и аналоги
Смотреть все
Unabyss
НовоеUnabyss превращает разрозненные данные из Slack, Notion и Drive в единый актуальный контекст для любых AI-агентов через MCP.

Tinkerer Club
НовоеЗакрытое комьюнити для тех, кто строит свою цифровую инфраструктуру, хостит локальные ИИ и уходит от облачной зависимости.

SCRAPR
НовоеAPI для парсинга веб-данных, которое вытаскивает JSON напрямую из сетевых запросов. Забудьте про поломанные селекторы и тяжелые браузеры.

Rover by rtrvr.ai
НовоеПревратите браузер в автономного ИИ-агента. Автоматизируйте клики, сбор данных и заполнение форм с помощью простых текстовых команд.

QuickCompare by Trismik
НовоеQuickCompare от Trismik помогает выбрать идеальную LLM для вашего проекта на основе реальных данных, а не догадок.

Powabase
НовоеPowabase — это платформа для создания AI-приложений на базе Postgres. Объединяет RAG, агентов и визуальные рабочие процессы в одном бэкенде.