
TurboQuant
Алгоритм сжатия от Google для LLM, который ужимает KV-кэш в 6 раз без потери точности.
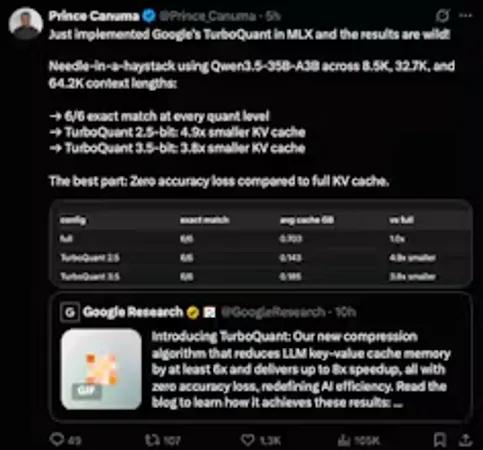
Обзор TurboQuant
TurboQuant — это свежий подход к квантованию от Google, представленный на ICLR 2026. Суть в том, что обычные методы сжатия часто добавляют лишние биты для хранения самих констант сжатия, что сводит пользу на нет. TurboQuant использует PolarQuant для перевода координат в углы и QJL для точной коррекции ошибок. В итоге получается компактный кэш, который летает даже на сложных задачах вроде поиска иголки в стоге сена.
Главные функции
Сжатие 6x
Уменьшает размер KV-кэша минимум в 6 раз, сохраняя исходную точность модели.
Нулевая потеря точности
Математически выверенное сжатие гарантирует, что качество ответов не проседает.
Никакого дообучения
Алгоритм работает «из коробки», не требуя сложного файн-тюнинга или переобучения.
Ускорение на H100
При 4-битном квантовании скорость вычисления attention вырастает в 8 раз на GPU H100.
Плюсы и минусы
Преимущества
- Минимальные накладные расходы на память
- Работает с любыми open-source моделями вроде Gemma или Mistral
- Быстрее стандартных 32-битных вычислений
Недостатки
- Требует внедрения на уровне архитектуры движка
- Сложная математическая база для самостоятельной реализации
Для кого и как использовать?
Работа с длинными контекстами
Позволяет моделям обрабатывать огромные документы без переполнения памяти.
Поиск по векторам
Ускоряет similarity-поиск, минимизируя накладные расходы на хранение квантованных констант.
Оптимизация серверов
Снижает затраты на VRAM, позволяя запускать более тяжелые модели на доступном железе.
Частые вопросы
Похожие нейросети и аналоги
Смотреть все
ZeroGPU
НовоеZeroGPU — это слой для оптимизации ИИ-инференса, который переносит рутинные задачи с дорогих моделей на быстрые и дешевые SLM.

Zernio WhatsApp API
НовоеЕдиный API для управления соцсетями и рекламными кабинетами. Опубликуй контент в 15+ сетях через один запрос.

Vox
НовоеVox — это расширение для GitHub Copilot, которое дает вам возможность общаться с ИИ голосом. Забудьте про клавиатуру, просто говорите и слушайте ответы.

TryCase
НовоеTryCase дает вашему ИИ-кодеру личный Linux-десктоп для тестирования кода. Агент сам запускает приложение и шлет вам пруфы.

Timbal AI
НовоеПлатформа для создания и деплоя ИИ-агентов, рабочих процессов и интерфейсов для бизнеса. Позволяет управлять инфраструктурой без вендор-лока.

Terminal Mode by Even Realities
НовоеВыводите состояние ИИ-агентов прямо на линзы очков Even G2. Контролируйте код, не отрываясь от кофе или прогулки.