
Pinecone
Pinecone - управляемая векторная база данных для ML. Храните, индексируйте и ищите миллиарды векторов с минимальными усилиями.
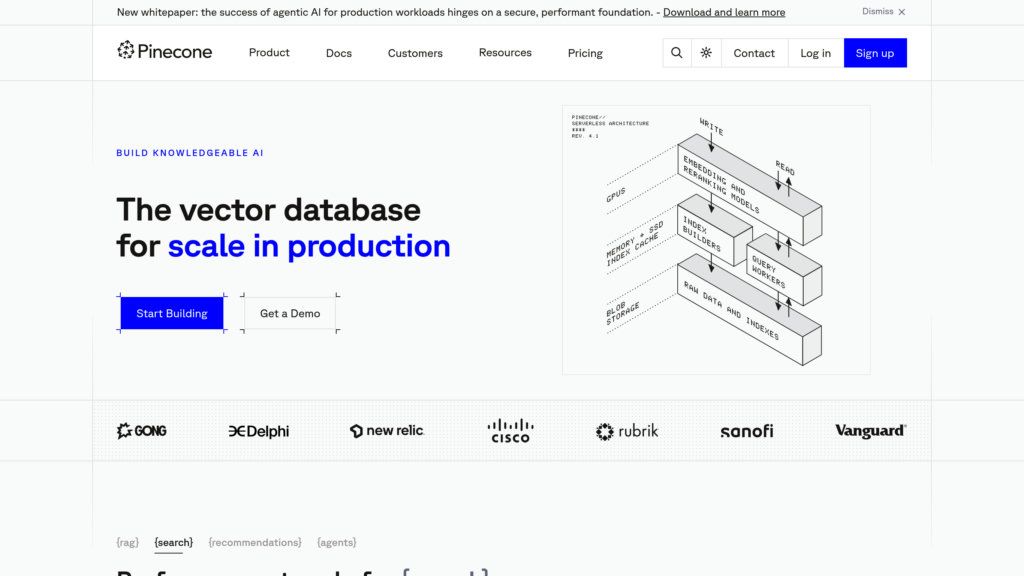
Обзор Pinecone
Pinecone — это управляемый сервис векторной базы данных, оптимизированный для приложений машинного обучения. Он позволяет эффективно хранить, индексировать и выполнять запросы к высокоразмерным векторным данным, абстрагируя управление инфраструктурой. Сервис автоматически масштабируется под нагрузку, обеспечивает вставку данных в реальном времени и обладает надежными функциями безопасности. Продукт решает проблему сложности управления собственной векторной базой данных, особенно при работе с большими объемами данных и высокими требованиями к производительности. Разработчики и специалисты по данным могут сосредоточиться на создании ML-приложений, таких как системы рекомендаций или поиск по сходству, не беспокоясь о масштабировании, обслуживании и мониторинге инфраструктуры.
Главные функции
Полностью управляемая инфраструктура
Pinecone берет на себя все задачи по обслуживанию, масштабированию, мониторингу и обновлению бэкенда, позволяя вам сосредоточиться на разработке.
Масштабируемая серверная архитектура
Автоматически масштабируется для эффективной обработки миллиардов векторов, адаптируясь к изменяющейся нагрузке.
Индексация и вставка данных в реальном времени
Обеспечивает мгновенное добавление и индексацию новых данных для актуальных результатов поиска без простоев.
Низкая задержка и высокая точность поиска
Использует оптимизированные алгоритмы для быстрого и точного поиска ближайших соседей и сходства в больших наборах данных.
Интеграция через API
Легко интегрируется в существующие ML-воркфлоу и конвейеры данных благодаря простому и интуитивно понятному API.
Плюсы и минусы
Преимущества
- Снижает операционные расходы и сложность управления базами данных.
- Высокая производительность для поиска сходства и рекомендательных систем.
- Соответствие стандартам безопасности (SOC 2, GDPR, HIPAA).
Недостатки
- Зависимость от качества входных данных и векторизации.
- Может быть дороже для небольших проектов по сравнению с self-hosted решениями.
- Требует понимания принципов работы векторных баз данных для эффективного использования.
Для кого и как использовать?
ML Engineer
Быстрое создание и развертывание систем поиска по сходству изображений или текста, а также рекомендательных систем без необходимости управлять инфраструктурой.
Data Scientist
Эффективный анализ и поиск в больших наборах векторных данных для выявления паттернов и аномалий.
Backend Developer
Интеграция AI-функций, таких как семантический поиск или обнаружение дубликатов, в веб-приложения с минимальными усилиями по настройке базы данных.
Частые вопросы
Похожие нейросети и аналоги
Смотреть все
Scholé
НовоеScholé превращает обучение сотрудников в персональный AI-тренинг, адаптированный под конкретные рабочие инструменты и задачи.

Unabyss
НовоеUnabyss превращает разрозненные данные из Slack, Notion и Drive в единый актуальный контекст для любых AI-агентов через MCP.

traceAI
НовоеTraceAI — это open-source платформа для отладки и оценки AI-агентов, которая понимает логику работы LLM, а не просто HTTP-запросы.

Second Brain for AI
НовоеЕдиная память для всех ваших ИИ-инструментов. Храните заметки и контекст в своем облаке Cloudflare и используйте их в Claude, ChatGPT или Cursor.

SCRAPR
НовоеAPI для парсинга веб-данных, которое вытаскивает JSON напрямую из сетевых запросов. Забудьте про поломанные селекторы и тяжелые браузеры.

Rover by rtrvr.ai
НовоеПревратите браузер в автономного ИИ-агента. Автоматизируйте клики, сбор данных и заполнение форм с помощью простых текстовых команд.