8 июня 2026 вышло первое крупное эмпирическое исследование по AI-агентам на реальных продакшн-данных — не на синтетических задачах, не на студенческих экспериментах, а на 10 000 пар сессий живых пользователей. Авторы: Джереми Янг из Harvard Business School и Джерри Ма из Perplexity. Главная цифра: AI-агент экономит 87% времени и 94% стоимости знаниевой работы по сравнению с обычным чат-ботом.

Разбираем методологию, цифры и что это значит для вайбкодеров и всех, кто работает со знаниями.
Исследование Harvard + Perplexity (arXiv 2606.07489) сравнило AI-агент (Perplexity Computer) с чат-ботом (Perplexity Search) на идентичных задачах. Результат: агент работает автономно 26 минут против 33 секунд у чат-бота (разрыв 48×), экономит 87% времени и 94% стоимости. 23% задач агентов — те, которые пользователи никогда не задавали чат-боту. В статье: методология, ключевые цифры, импликации для рынка труда.
Как устроено исследование и почему оно отличается от других
10 000 пар сессий — один и тот же пользователь, одна и та же задача, разные инструменты. Это natural experiment, а не лабораторные условия.
Большинство исследований продуктивности с AI выглядят так: берут группу людей, дают им синтетические задачи, измеряют разницу. Проблема — искусственные условия дают искажённые результаты.
Здесь иначе. Авторы сравнили два продукта Perplexity: Search (запущен в 2022, conversational ответы) и Computer (запущен 25 февраля 2026, агент-оркестратор). Период наблюдения — 90 дней, с 27 февраля по 27 мая 2026.
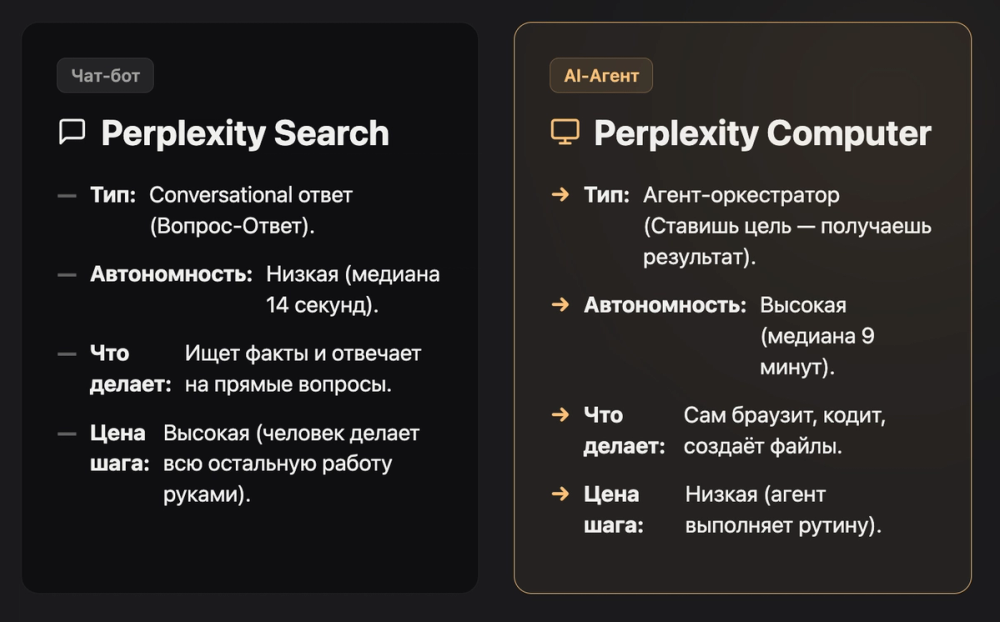
Метод: matched pairs. Один и тот же пользователь отправлял практически идентичный запрос (cosine similarity > 0.99) сначала в один продукт, потом в другой. 10 000 таких пар. Задача одна — инструмент разный. Это убирает конфаундинг: разница в результатах объясняется только инструментом, не задачей и не пользователем.
Принципиальное различие между инструментами:
| Perplexity Search | Perplexity Computer | |
|---|---|---|
| Тип | Conversational ответ | Агент-оркестратор |
| Автономность | Низкая | Высокая |
| Что делает | Отвечает на вопрос | Сам ищет, браузит, кодит, создаёт документы |
| Стоимость входа | Низкая | Высокая (нужно правильно поставить задачу) |
| Стоимость шага | Высокая (человек делает руками) | Низкая (агент выполняет) |
Что означает 48× разрыв в автономности
26 минут автономной работы за сессию у агента против 33 секунд у чат-бота. Разрыв стабилен во всех 18 доменах — от науки до местных сервисов.

Главный замер — сколько машина работает сама, без участия человека.
Агент: 26 минут за сессию (медиана 9 минут). Чат-бот: 33 секунды (медиана 14 секунд). 48× по средним значениям, 40× по медиане.
Важнее то, что разрыв держится во всех 18 исследованных доменах. Минимум: Science — 26×. Максимум: Local — 75×. Нет ни одной области, где чат-бот хотя бы приближается к агенту по автономности.
И вот неожиданный результат: больше автономности не означает хуже качество. Уровень значимого недовольства (meaningful dissatisfaction) у агента — 1.3% против 2.9% у чат-бота. Снижение на 55%. Закономерность прямая: чем больше агент делает сам, тем реже пользователь недоволен результатом.
Что происходит с пользователем за это время: follow-up запросы меняют характер. Вместо «теперь сделай X» — «проверь это» и «добавь ещё». Человек переходит из режима исполнителя в режим проверяющего.
Откуда берутся 87% экономии времени и 94% стоимости
Три независимых метода дали схожие результаты: 87%, 84% и 96% экономии времени. Точка безубыточности — 20 минут ручной работы.
Авторы не ограничились одним подсчётом — использовали три независимых метода, чтобы проверить друг друга.
Метод 1 (основной): считает инструменты, которые агент использовал в сессии, и оценивает, сколько времени человек потратил бы на те же действия вручную. Результат: 269 минут (Search + человек) против 36 минут (Computer + человек). Экономия 87% времени и 94% стоимости.
Стоимость считалась по реальным зарплатам из Bureau of Labor Statistics по конкретным профессиям. Экономия в деньгах выше, чем во времени, потому что высокооплачиваемые домены — финансы, юриспруденция, программирование — выигрывают больше всего.
Метод 2 (LLM-оценка): независимая модель оценивала время по тексту запросов. Получилось 84% времени и 93% стоимости. Цифры сошлись.
Метод 3 (интервью): 25 пользователей назвали субъективное ускорение от 5× до 300×. Медиана — 25× (это 96% сокращения времени).
| Метод | Экономия времени | Экономия стоимости |
|---|---|---|
| Tool-based (основной) | 87% | 94% |
| LLM-оценка | 84% | 93% |
| Интервью (медиана) | 96% | — |
Самый показательный кейс — программирование. Search + человек: 596 минут (~10 часов). Computer + человек: 48 минут. Экономия: 92% времени и 96% стоимости.
Точка безубыточности: чтобы конкурировать с агентом по стоимости, человек должен выполнить все ручные шаги задачи быстрее 20 минут. Для многошаговой исследовательской или аналитической работы это нереально.
Что агенты меняют в задачах, а не только в скорости?
Агент расширяет не только скорость — он расширяет сами задачи. 23% запросов к агенту — те, которые пользователи никогда не задавали чат-боту.

Это самая неочевидная находка исследования. Агенты не просто ускоряют существующую работу — они создают спрос на работу, которую раньше не делали, потому что было слишком дорого.
23% задач в Computer — Task Statements, которые те же пользователи никогда не отправляли в Search. Концентрация: разработка ПО, документация, визуализация данных. Задачи, которые раньше требовали нанять специалиста или потратить несколько часов, теперь укладываются в сессию.
Три измерения расширения:
Горизонтальное (выход за рамки профессии). Доля кросс-профессиональных запросов: 59% у Computer против 50% у Search. Самый большой разрыв — Management & Entrepreneurship: +19 п.п. Менеджеры напрямую делают работу маркетологов, аналитиков, разработчиков.
Вертикальное (когнитивная сложность). По таксономии Блума высшие уровни (Анализ → Оценка → Создание): 76% у Computer против 55% у Search. Уровень «Создание»: 50% против 26% — вдвое больше создающей работы.
Глубина. Среднее число знаниевых доменов на запрос: 2.40 у Computer против 1.74 у Search (+38%). Почти в три раза чаще агенту дают задачи, требующие трёх и более областей знаний.
Максим: «У меня загорелись глаза, когда увидел эти 23% новых задач. Это же точно то, что происходит в нашей работе: с GoBanana мы начали делать задачи, которые раньше просто не брали — слишком долго, слишком дорого. Агент делает их за вечер. Сделал — получил цифру.»
Агенты убивают поиск и чат-боты?
Нет. Пользователи Computer стали делать на 1.05 запроса в день больше в Search. Агент и чат-бот — разные инструменты для разных задач.
Логичное опасение: если агент делает всё, зачем вообще чат-бот? Исследование даёт чёткий ответ — это не замещение, это специализация.
DiD-анализ (difference-in-differences): использование Computer увеличивает ежедневные Search-запросы на +1.05. То есть те, кто работает с агентом, больше, а не меньше обращаются к обычному поиску.
Механика понятная. Теоретическая модель авторов: у каждой задачи есть пороговое число шагов s⁎. Задачи короче порога — остаются в чате (дёшево, быстро). Задачи длиннее — мигрируют к агенту. Чем сложнее задача, тем больше выгода от агента.
Результат: агент разгружает чат от сложных многошаговых задач. Чат становится инструментом для быстрых вопросов — и используется чаще, потому что пользователь теперь работает с обоими продуктами осознанно.
Как это меняет рынок труда — 3 сдвига
От специализации к генерализму. От исполнения к супервизии. От снижения издержек к созданию новой ценности.

Сдвиг 1: оператор → супервайзер. Человек перестаёт пошагово инструктировать, начинает ставить цели и проверять результат. Это другой навык. Умение правильно поставить задачу и критически оценить выход становится важнее умения самому выполнить шаги.
Сдвиг 2: специалист → генералист. 2.4 домена знаний на запрос — один человек с агентом покрывает то, что раньше требовало команды. Менеджер+агент напрямую делает работу маркетолога, аналитика, разработчика. T-shaped специалист с навыком делегирования агенту выигрывает у глубокого узкого эксперта.
Сдвиг 3: сокращение издержек → создание ценности. −94% стоимости — это не «на 15% эффективнее». Это другая юнит-экономика. Если конкурент внедряет агентов, а компания нет — это конкуренция с компанией, у которой стоимость знаниевой работы в 15 раз ниже. Плюс 23% задач — новые. Агенты не только режут расходы, они создают возможности, которых без них не было.
20-минутная точка безубыточности — простой тест: если задача занимает у вас больше 20 минут ручного труда, агент уже дешевле.
Что здесь не так — честные ограничения
Early adopter bias, working paper, оценочный метод времени. Цифры убедительные, но не финальные.
Авторы сами честно прописывают caveat'ы — это признак хорошей науки.
Выборка: пользователи Perplexity Computer — AI-энтузиасты, не средний офисный работник. Цифры могут быть завышены относительно массового внедрения.
Быстро меняющийся продукт: за 90 дней Computer активно апдейтился. Паттерны первых недель не обязательно повторятся через год.
Оценки времени: tool-based метод опирается на предположения о том, сколько человек потратил бы на ручное выполнение. Чувствительность проверена, но это всё ещё оценки, не прямые замеры.
Working paper: исследование не прошло peer review. До воспроизведения независимыми командами цифры — убедительная гипотеза, не установленный факт.
Но: три независимых метода дали схожие результаты (87%, 84%, 96%). Это сложно объяснить случайностью методологии.
FAQ
Что такое исследование Harvard и Perplexity по AI-агентам?
Working paper «How AI Agents Reshape Knowledge Work» (arXiv 2606.07489), опубликованный 8 июня 2026. Авторы — Jeremy Yang (Harvard Business School) и Jerry Ma (Perplexity). Первое эмпирическое исследование AI-агентов на реальных продакшн-данных: 10 000 пар сессий за 90 дней.
Чем агент отличается от чат-бота в этом исследовании?
Perplexity Search — conversational инструмент: задал вопрос, получил ответ. Perplexity Computer — агент-оркестратор: ставишь цель, агент сам ищет, браузит, пишет код, создаёт документы, дёргает API и не останавливается, пока не выдаст результат.
Почему экономия стоимости (94%) больше, чем экономия времени (87%)?
Потому что высокооплачиваемые домены — финансы, юриспруденция, программирование — получают наибольший выигрыш. Один час юриста стоит дороже одного часа ассистента. Агент экономит часы там, где час стоит дорого.
Что значит 23% новых задач?
23% запросов к Perplexity Computer — это задачи, которые те же пользователи никогда не отправляли в Search. Агент создаёт спрос на работу, которую раньше не делали из-за высокой стоимости: ПО-разработка, документация, визуализация данных.
Как использовать эти данные для принятия решений?
Простой тест: возьмите любую повторяющуюся задачу команды. Если она занимает больше 20 минут ручного труда — агент дешевле. Для задач длиннее 4-5 часов (как в кейсе с программированием) экономия составляет 90%+ и времени, и денег.
Почему пользователи Computer стали больше пользоваться Search?
Комплементарность, не замещение. Агент берёт сложные многошаговые задачи. Это освобождает когнитивные ресурсы для генерации новых вопросов и быстрых поисков. Оба инструмента растут вместе.
Насколько достоверны цифры?
Три метода — 87%, 84%, 96% — сошлись. Но выборка — early adopters, не массовый пользователь. Исследование не peer-reviewed. Цифры стоит принимать как нижнюю оценку для AI-энтузиастов и как гипотезу для остальных.
Глоссарий
AI-агент — программа, которая самостоятельно выполняет многошаговые задачи: ищет информацию, запускает код, создаёт файлы, дёргает внешние API. В отличие от чат-бота не останавливается после одного ответа.
Conversational AI — интерфейс «вопрос → ответ». Чат-бот вроде ChatGPT или Perplexity Search. Каждый шаг задачи требует отдельного запроса от человека.
Knowledge work (знаниевая работа) — профессиональная деятельность, основанная на обработке информации: анализ, исследования, написание текстов, программирование, консультирование.
Natural experiment (естественный эксперимент) — метод исследования, где условия эксперимента создала жизнь, а не лаборатория. Здесь: один и тот же пользователь отправил одну и ту же задачу двумя способами.
Matched pairs — методология, при которой сравниваются пары наблюдений с максимально похожими условиями. В данном случае: идентичный пользователь + idентичная задача, разные инструменты.
Косинусное сходство (cosine similarity) — метрика похожести двух текстов. Значение > 0.99 означает, что запросы практически идентичны по смыслу.
Таксономия Блума — классификация образовательных целей по когнитивной сложности: Помнить → Понимать → Применять → Анализировать → Оценивать → Создавать. Высшие уровни — Анализ, Оценка, Создание.
DiD (difference-in-differences) — статистический метод оценки причинно-следственных эффектов. Сравнивает изменения в группе с воздействием (пользователи Computer) и без воздействия (пользователи только Search).
T-shaped специалист — человек с глубокой экспертизой в одной области и базовыми знаниями в нескольких смежных. С агентом T-форма расширяется: одному человеку доступно то, что раньше требовало команды.
Полные данные и методология — в оригинальном тексте исследования на arXiv и блоге Perplexity Research. Разбор бизнес-импликаций — на FourWeekMBA.
Смотрите каталог AI-агентов на VibeCoderz — 297 ниш, инструменты под конкретные задачи и профессии.
Если хотите разобраться, как встроить агентов в конкретный рабочий процесс, запишитесь на консультацию к Максиму.
Обновлено: июнь 2026.
Источники: arXiv 2606.07489, Perplexity Research Blog, MarkTechPost.