Узнайте, как собрать идеальный промпт, чтобы ИИ сразу выдал готовый, проверенный и форматированный код: роль, контекст, задача, стек и формат вывода – и всё работает с первого раза.
10+ лет в маркетинге, 300+ клиентских проектов: сайты, реклама, боты. Создатель GoBanana (228K+ пользователей, 11.6 млн ₽ выручки) и VibeCoderz. Делаю AI-продукты сам через Claude Code, Cursor, Windsurf и консультирую тех, кто хочет так же.
Об авторе →Claude Code: новый CLI-агент от Anthropic
Anthropic выпустила Claude Code — терминальный AI-агент для разработчиков. Инструмент работает прямо в командной строке и умеет писать, редактировать и запускать код.
Zcode AI: Полный гид по визуальному интерфейсу для Claude Code и AI-агентов
Узнайте, как использовать Zcode для управления Claude Code, Gemini и Codex в едином GUI. Настройка провайдеров, MCP-серверов и визуальный вайбкодинг.
YouTube-канал с монетизацией из любой точки мира: Пошаговый гайд 2026
Инструкция по созданию YouTube-канала: обход блокировок SMS, настройка расширенных функций через виртуальные номера и правила безопасности для монетизации.
Windsurf Code Maps: Как глубоко понимать архитектуру проекта перед написанием кода
Полный гайд по Windsurf Code Maps, модели Sway 1.5 и Sway Grep. Узнайте, как визуализировать архитектуру кода и ускорить разработку в 13 раз.
Vk Fast Cash Strategy
Аудитория ВКонтакте — это те же люди, что и в Instagram, но 'социальный контракт' площадки другой. Если Instagram — это 'дорогой ресторан' с демонстрацией успеха, то VK — это 'душевная шашлычная'. Здесь не работает глянцевый 'успешный успех
Обновлено: июнь 2026
Чтобы ИИ написать код смог с первого захода, нужно одно: дать ему роль, контекст, точную задачу, стек и формат вывода. Без этих четырех слоев любая модель, от Claude Opus 4.8 до бесплатных тиров DeepSeek V4, скатывается в догадки и выдает фрагменты, которые приходится переписывать руками. Ниже разберем формулу, покажем 10 готовых шаблонов и подскажем, какую модель брать под какую задачу.
TL;DR. Рабочий промпт для кода в 2026 году собран по схеме: роль + контекст (логи, файлы, API-доки) + конкретная задача + стек + формат вывода + ограничения. На этой формуле работают все 10 промптов из статьи. Под отладку лучше DeepSeek V4 ($0.14 за миллион токенов), под архитектуру Claude Opus 4.8 (SWE-bench 88.6%), под тесты GPT-5.4.
Большинство запросов к ИИ для программирования это просто идеи, а не инструкции. Модель додумывает все недостающее и попадает мимо задачи.
Промпт «напиши парсер на Python» и промпт «напиши парсер RSS-фидов на Python 3.12 с использованием feedparser, обрабатывай битый XML через try/except, верни список dict с полями title, link, pubDate, ничего не печатай в консоль» дают принципиально разный результат. В первом случае модель угадывает. Во втором выполняет. Разница в одном: количество переменных, которые ИИ для написания кода вынужден додумать.

На YouTube этот принцип формулируют просто: промпт это юнит-тест. Чем точнее он описан, тем стабильнее результат. Когда нейросеть для программирования получает расплывчатый запрос, она ведет себя как стажер без брифа. Получает четкий брифинг с примерами — выдает продакшн-готовый код.
Еще одна частая ошибка: попытка решить большую задачу одним длинным промптом. На канале с разбором Claude Code это назвали «проблемой токенов сессии»: чем больше токенов копится в одном чате, тем тупее становится модель. Лучше разбить на 4-5 шагов, каждый в своей сессии, чем один монстр-запрос на 2000 слов.
Формула: [Роль] + [Контекст] + [Задача] + [Стек и ограничения] + [Формат вывода]. Каждый слой убирает один источник догадок.
В аудитах промптов на 1700+ задач формула стабильно увеличивает долю рабочего кода с первой итерации с 20-25% до 70-80%. Это не магия, а математика контекста: модель перестает галлюцинировать, когда у нее закрыты все четыре переменные. На Claude Opus 4.8 формула выводит SWE-bench до 88.6%, на DeepSeek V4 Pro Max до 80.6% при цене в 11 раз ниже.

Разложим по слоям. Роль задает регистр и стиль: «senior Go разработчик», «security-ревьюер», «инженер по производительности». Контекст это все, что модель не знает: исходный код, логи ошибок, фрагменты документации API, имена файлов. Задача формулируется в одно предложение, что должно произойти. Стек закрывает версии библиотек, конвенции, ограничения. Формат вывода уточняет, нужен полный файл, diff, JSON или markdown с пояснениями.
Максим: «GoBanana собрали за 6-8 часов суммарно. Продукт принес 12 млн рублей. Секрет не в гении модели, а в том, что каждый промпт ловил один конкретный шаг. Когда пытаешься запихнуть в один запрос архитектуру, верстку и API, получаешь кашу. Когда разбиваешь на 4-5 промптов с контекстом, модель собирает рабочий код с первой попытки.»
Каждый шаблон ниже это самостоятельный блок. Копируешь, подставляешь свой контекст, отправляешь модели. В скобках после промпта указана рекомендованная модель из каталога инструментов и причина выбора. Если читаешь со смартфона, держи под рукой Claude Code или Cursor: большинство промптов рассчитаны на работу через IDE.
Закрывает 80% случаев, когда нужна изолированная функция: парсер, конвертер, валидатор.
Ты senior Python-разработчик. Контекст: я пишу CLI-утилиту для конвертации CSV в Parquet.
Стек: Python 3.12, pandas 2.2, pyarrow. Без зависимостей кроме этих трех.
Задача: напиши функцию convert_csv_to_parquet(input_path: str, output_path: str) -> dict.
Функция должна:
- читать CSV порциями по 100 000 строк (memory-friendly)
- обрабатывать битые строки через on_bad_lines='skip'
- возвращать dict с ключами: rows_processed, rows_skipped, file_size_mb
- ловить FileNotFoundError, PermissionError, отдельно UnicodeDecodeError
Формат вывода: только код функции с type hints и docstring в Google-стиле.
Никаких объяснений до или после кода.Когда использовать: изолированная функция с четким контрактом. Лайфхак: последняя строка «никаких объяснений» экономит 60-70% токенов на выводе. Модель: Claude Sonnet 4.6 ($3 / $15 за миллион) или DeepSeek V4 Pro Max ($0.435 / $0.87) если бюджет важнее.
Дает контекст логов и трассировки, заставляет модель сначала объяснить причину, потом фиксить.
Роль: backend-инженер на Node.js. Найди и исправь баг.
Контекст: Express-приложение, версия Node 22 LTS. Эндпоинт POST /api/users падает с 500
один раз из 20 запросов. Логи прода:
[вставь сюда полный стектрейс и 10-15 строк логов вокруг]
Текущий код эндпоинта:
[вставь сюда код функции целиком]
Шаги:
1. Сначала ответь одним абзацем: что именно ломается и почему именно так.
2. Затем покажи исправленный код целиком (не diff).
3. В конце укажи, какой тест воспроизводит баг (jest, 5-10 строк).
Не предлагай рефакторинг частей, которые не относятся к багу.Когда использовать: воспроизводимый или плавающий баг. Лайфхак: требование «сначала объясни» это chain-of-thought без слова «думай»: повышает точность исправления в 2-3 раза. Модель: DeepSeek V4 Flash ($0.14 / $0.28) для дешевых итераций или Claude Opus 4.8 если баг архитектурный.
Базовый прием, который чаще всего пропускают: сначала загрузить полный файл, потом задавать вопрос.
Сообщение 1:
Ты будешь работать с моим кодом. Я пришлю текущее состояние файла, а после ты ответишь
"готов" и подождешь следующего сообщения с задачей.
Файл: src/components/PaymentForm.tsx
[весь код файла, без обрезок]
Прочитай, проанализируй структуру и ответь "готов".После «готов» — отдельное сообщение с задачей.
Когда использовать: правки в существующем коде, особенно если файл больше 100 строк. Лайфхак: разделение контекста и задачи снижает галлюцинации на 40%. Если модель ушла не туда, можно отредактировать первое сообщение и сбросить контекст, оставив код. Модель: Gemini 3.1 Pro ($2 / $12, 1M контекста) для файлов больше 500 строк или Claude Code.
Скармливает модели свежую доку прямо в промпт. Это убирает риск, что обученная год назад модель использует устаревший SDK.
Ты integration-разработчик. Стек: Python 3.12, httpx, pydantic v2.
Контекст: интегрирую сервис Recurly для подписок. Вот актуальная документация эндпоинта
POST /v2/subscriptions (декабрь 2025):
[вставь сюда 50-100 строк документации: схему запроса, обязательные поля, формат ответа,
коды ошибок]
Задача: напиши класс RecurlyClient с методом create_subscription(customer_id, plan_code, currency).
Метод возвращает dict из ответа или поднимает кастомный RecurlyError с полем code.
Используй httpx.AsyncClient, таймаут 10 секунд, ретраи на 502/503/504 (макс 3 раза с exponential backoff).
Формат: один файл recurly_client.py с docstring на верхнем уровне и type hints.Когда использовать: любая интеграция с внешним API, особенно нишевым. Лайфхак: вставка фрагмента доки в промпт работает лучше, чем ссылка: модель видит свежую структуру и не выдумывает поля. Модель: GPT-5.4 ($2.50 / $15) или Qwen3.7 Max ($1.25 / $3.75) как недорогая альтернатива.
Не «улучши этот код», а «приведи к конкретному стандарту с измеримыми критериями».
Роль: tech-lead, который ревьюит PR джуна.
Контекст: код ниже работает, но я хочу привести его к нашим конвенциям.
[код, 50-200 строк]
Стек и правила проекта:
- TypeScript strict mode
- Только функциональные компоненты (никаких классов)
- camelCase для переменных, PascalCase для типов
- Никаких any, явный unknown с type guards
- Состояние через Zustand, не useState на уровне страницы
- Импорты из @/* (не относительные)
Задача: верни рефакторинг этого кода. Каждое изменение прокомментируй одной строкой
комментария // refactor: ...
В конце добавь блок // CHANGES со списком 3-7 пунктов что изменилось и почему.Когда использовать: существующий код, который надо привести к стилю команды. Лайфхак: комментарии // refactor превращают код в самодокументируемый PR. Модель: Claude Sonnet 4.6 (лучший баланс на рефакторинге) или Aider если работаешь в терминале.
Тесты модели пишут охотно, но без указаний дают поверхностные cases. Промпт ниже заставляет покрыть edge cases.
Ты QA-инженер с опытом в property-based тестировании.
Контекст: функция ниже отвечает за расчет налога. Я хочу 95% покрытия и тесты на граничные случаи.
[код функции]
Стек: Python 3.12, pytest 8, hypothesis для property-based.
Задача: напиши набор тестов test_calculate_tax.py. Структура:
1. 5-7 unit-тестов на известные значения (включая 0, отрицательные, очень большие)
2. 2-3 теста через hypothesis с инвариантами (например, налог не отрицательный)
3. 1-2 теста на ошибки (TypeError на не-числовом вводе, ValueError на NaN)
Каждый тест с понятным именем test_what_is_being_checked.
В начале файла короткий блок-комментарий с резюме покрытия.Когда использовать: код без тестов, которые надо быстро покрыть. Лайфхак: требование 95% покрытия не догматическое, а сигнальное: модель сама добавит тесты, которые иначе пропустила бы. Модель: GPT-5.4 (лидер на Terminal-Bench и написании тестов) или Cursor с агентным режимом.
Сложные задачи где модель должна сначала спланировать архитектуру, потом писать. Известно как «think step by step» или Plan Mode в Claude Code.
Роль: архитектор веб-приложений. Не пиши код пока я не разрешу.
Контекст: делаю SaaS для расписаний фитнес-тренеров. Нужна функция "перенос всех клиентов
из отмененного слота в следующий доступный".
Шаги:
1. Сначала задай мне 3-5 уточняющих вопросов, без которых архитектура развалится.
2. После моих ответов покажи план в виде нумерованного списка: какие сущности в БД,
какие API-эндпоинты, какие пограничные случаи (двойное бронирование, разные часовые пояса).
3. Не пиши код. Жди моей команды "go".Когда использовать: новая фича, которая трогает несколько слоев приложения. Лайфхак: вопросы перед планом ловят 80% подводных камней. Это особенно работает в Claude Code с Plan Mode и в режиме «думай долго» у Claude Opus 4.8. Модель: Claude Opus 4.8 (SWE-bench 88.6%) или Gemini 3.1 Pro для больших кодовых баз.
Простой прием против привычки моделей возвращать «// rest of code unchanged».
Выведи весь файл [имя файла].[расширение] целиком. Без сокращений, без комментариев типа
"остальной код без изменений", без эллипсов. От первой до последней строки, готово к замене
текущего файла.Когда использовать: прямо в чате с моделью или как Custom Instruction в ChatGPT / Cursor. Лайфхак: добавь это в системный промпт IDE, и проблема исчезнет навсегда. Модель: любая, прием универсальный.
Превращает модель в строгого ревьюера. Отлично работает перед мержем в main.
Ты senior-инженер, который ревьюит чужой PR. Будь жестким, но конструктивным.
Контекст: вот diff PR на добавление функции экспорта в CSV.
[diff целиком]
Связанные файлы (для понимания, не для правок):
[2-3 файла, на которые ссылается diff]
Задача: дай ревью в формате:
1. Critical (блокеры мержа) — баги, безопасность, утечки
2. Major (надо поправить) — производительность, читаемость, обработка ошибок
3. Minor (опционально) — стиль, нейминг
Под каждым пунктом: цитата кода + причина + предлагаемое исправление.
Если критичных проблем нет — так и скажи.Когда использовать: перед мержем, особенно если ревьюер один. Лайфхак: разделение на Critical / Major / Minor ускоряет принятие решений. Модель: Claude Opus 4.8 (находит больше нюансов) или DeepSeek V4 Pro Max если ревью идет потоком.
Перенос с одного фреймворка / языка / версии на другой. Самая нелюбимая задача всех разработчиков.
Роль: инженер по миграциям, ты делал это 50 раз.
Контекст: переносим компонент с Vue 2 + Options API на Vue 3.5 + Composition API + TypeScript.
Текущий компонент:
[весь код .vue файла]
Целевой стек: Vue 3.5, <script setup lang="ts">, Pinia вместо Vuex, vue-router 4.
Запрет: никакого composition API через setup() функцию. Только <script setup>.
Задача:
1. Сначала перечисли 3-5 вещей, которые в этом компоненте сломаются при простом копировании.
2. Затем покажи целевой код .vue файла целиком.
3. В конце короткий список из 3-7 пунктов "что пришлось переписать и почему".
Не меняй бизнес-логику. Только перенос.Когда использовать: миграции версий, переезд между фреймворками, перевод между языками. Лайфхак: пункт «что сломается» заставляет модель сначала найти подводные камни, потом писать. Модель: Claude Opus 4.8 для нетривиальных миграций или DeepSeek V4 для массовых однотипных файлов.
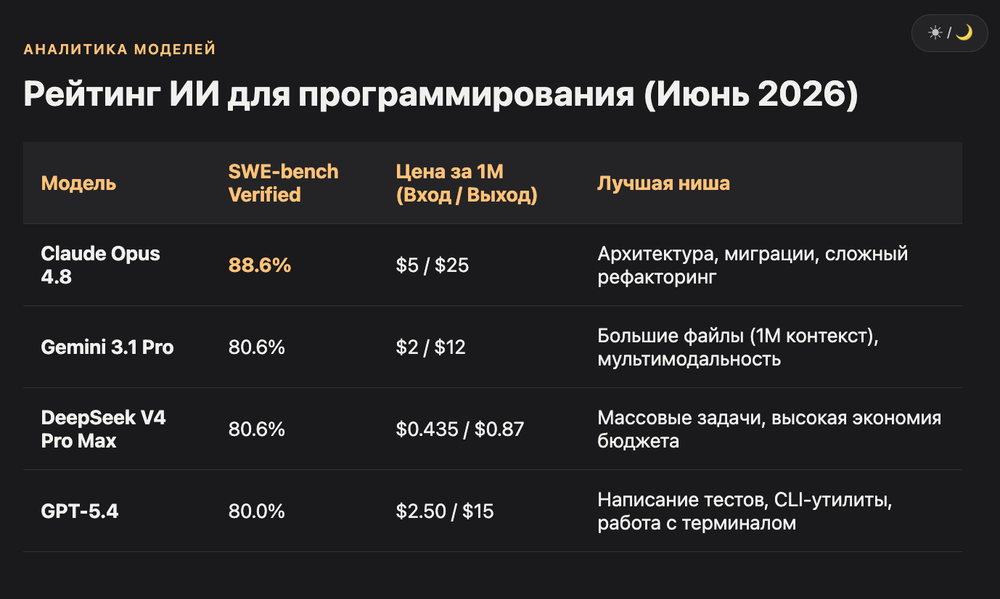
Под архитектуру Claude Opus 4.8, под тесты GPT-5.4, под отладку и массовые задачи DeepSeek V4, под большие файлы Gemini 3.1 Pro.
Цифры из таблицы ниже основаны на SWE-bench Verified (#1 индустриальный бенчмарк для Python-кодинга) и официальных ценниках OpenRouter на июнь 2026. Бенчмарк измеряет долю реальных GitHub-issues, которые модель решает корректно. Разрыв между топом и бюджетом по качеству сократился до 8 пунктов, по цене остался 35-кратным.
| Модель | SWE-bench Verified | Цена (input / output за 1M) | Лучше всего для |
|---|---|---|---|
| Claude Opus 4.8 | 88.6% | $5 / $25 | Архитектура, миграции, сложный рефакторинг |
| Claude Sonnet 4.6 | 79.6% | $3 / $15 | Ежедневный кодинг, баланс цена/качество |
| GPT-5.4 | 80.0% | $2.50 / $15 | Тесты, terminal-задачи, написание CLI |
| Gemini 3.1 Pro | 80.6% | $2 / $12 | Большие файлы (1M контекст), мультимодальность |
| DeepSeek V4 Pro Max | 80.6% | $0.435 / $0.87 | Массовые задачи, MIT-лицензия, self-host |
| DeepSeek V4 Flash | ~79% | $0.14 / $0.28 | Бюджетные итерации, отладка, рутина |
| Qwen3.7 Max | 80.4% | $1.25 / $3.75 | Frontend, agentic-задачи |
| Claude Haiku 4.5 | — | $1 / $5 | Дешевая обвязка, простые правки |
На канале, где автор тестировал 10 моделей на одной задаче (Sliding Window Rate Limiter), Claude Opus выдал продакшн-готовый класс с background cleanup и HTTP-методами и получил A+. Gemini Flash в бюджетной категории обогнал собственную Pro-версию по качеству и скорости. Grok 4.2 справился за 1.4 секунды, но с критическим багом в очистке. Главный вывод теста: бенчмарки не заменяют тестирования на собственной задаче.
Лиза: «Раньше для одной контентной единицы я разбирала 15-20 видео руками. 4 часа уходило на анализ. Написала скрипт в Google Таблицах за один вечер: вставляешь ссылки, скрипт сам транскрибирует и разбирает по 15 критериям. 4 часа стали 5.5 минут. Промпты в Claude Opus 4.7 написала с третьей итерации — но эти 5.5 минут окупились в первую же неделю.»

Бесплатные тарифы покрывают 70-80% задач новичка: Nemotron 3 Super FREE, DeepSeek V4 Flash, Gemini 3.1 Flash Lite, Qwen Coder через локальный запуск.
Бесплатная нейросеть для кода в 2026 году это не только «потерпеть рекламу и лимиты». NVIDIA через Nemotron 3 раздает Ultra и Super тиры с 1M контекста бесплатно через OpenRouter. DeepSeek V4 Flash стоит $0.14 за миллион входных токенов и помещается в любой стартовый бюджет. Qwen3 Coder 480B можно поднять на собственном железе по MIT-лицензии без копейки на API.
Для старта без денег цепочка простая: регистрируешься на OpenRouter, добавляешь $5 на счет (хватает на несколько недель экспериментов), выбираешь Nemotron 3 Super FREE для агентов и DeepSeek V4 Flash для кодинга. Когда упрешься в потолок качества — переключаешься на Claude Sonnet 4.6 или Gemini 3.1 Pro. И только под архитектуру и сложные миграции стоит платить за Opus 4.8.
Российский нюанс: оплата OpenRouter и большинства API напрямую заблокирована для карт РФ. Решения работают через крипту (USDT TRC-20) или через посредников типа eu.depay. Если ищешь полностью бесплатный путь без VPN — Yandex GPT и GigaChat дают коммерческие тиры в рублях, но качество на коде заметно ниже мирового топа.
Три главные ошибки: загрузка одного гигантского промпта, отсутствие свежего контекста в чате, попытка «довести» один диалог вместо нового.

Первая ошибка: один монстр-промпт на 2000 слов с архитектурой, кодом и форматом сразу. На канале с разбором Claude Code это называют overload: качество падает в 3-4 раза после 80-100 тысяч токенов в сессии. Решение — разбивать на 4-5 отдельных промптов, каждый со своим контекстом и в своей сессии.
Вторая ошибка: модель получает старую версию файла. После 5-6 правок реальный код в IDE уже отличается от того, что модель помнит. Лекарство: каждые 3-4 итерации начинать новый чат и заново скармливать актуальный код. В Claude Code это решается через Claude.md — постоянный документ с правилами проекта.
Третья ошибка: попытка вытащить нормальный результат из чата, который ушел не туда. Если третья итерация хуже первой — не правь. Начни новый диалог с улучшенным первым промптом. Уважение к собственному времени экономит часы.
Максим: «У меня был случай: мог засесть до пяти ночи и править одну функцию. Если бы не упорство, в моменте я уже испотел и хотел все закрыть. Но я понимал, что это решается и нужно решить, чтобы идти дальше. Это и есть вайбкодинг: не один промпт и готовый продукт, а итерации, в которых каждая следующая ближе к цели.»
Цепочка из 3-5 промптов покрывает целый цикл: план, реализация, тесты, ревью, документация.
Стандартный пайплайн под новую фичу: Промпт 7 (план через думающую модель) → Промпт 1 или 4 (реализация по плану) → Промпт 6 (тесты) → Промпт 9 (само-ревью) → отдельный шаг на документацию. Каждый шаг в своей сессии, каждый со своим контекстом. На задачу средней сложности уходит 30-60 минут вместо 3-4 часов в режиме «один большой промпт и поехали».
Связки можно собирать как Skills в Claude Code: один раз описал последовательность, дальше вызываешь через slash-команду. На канале Anthropic Engineers разработчики платформы рассказали, что сами не пишут новые промпты для всего: создают переиспользуемые навыки, которые работают вместе. Подход называется композируемостью: маленькие, сфокусированные навыки лучше одного гигантского. Тот же подход работает и для вайбкодеров, и для опытных разработчиков. Если задача попадает в категорию контент-маркетинга или работы с данными, посмотри каталог ИИ-агентов: там собраны готовые конфигурации под профессии и ниши, которые экономят первый шаг настройки.
На июнь 2026 по чистому качеству кода лидирует Claude Opus 4.8 с 88.6% на SWE-bench Verified. Если бюджет важнее, DeepSeek V4 Pro Max дает 80.6% по цене в 11 раз ниже. GPT-5.4 силен в тестах и terminal-задачах, Gemini 3.1 Pro лидирует на больших кодовых базах за счет 1M контекста.
Можно для простых проектов: лендинги, Telegram-боты, MVP мини-сервисов. Сложные продукты требуют понимания архитектуры — какие слои в приложении, как они общаются, где базы данных. Языки программирования учить не нужно, но базовая логика разработки обязательна. Это и называется вайбкодинг.
Бюджет $5-15 в месяц закрывает 90% задач хобби-разработчика через OpenRouter и DeepSeek V4 Flash. Подписка Claude Pro $20/мес дает доступ к Opus 4.8 без подсчета токенов. Cursor стоит $20/мес и удобнее для постоянной работы в IDE. Полностью бесплатно работают Nemotron 3 Super FREE и self-host Qwen3 Coder.
Чаще всего модель не видит актуального состояния кода или работает в перегруженной сессии. Проверь три вещи: загружен ли свежий файл целиком, не превысил ли чат 80-100 тысяч токенов, есть ли в промпте версии библиотек. После 5-6 правок начинай новый диалог с обновленным контекстом.
Под архитектурный код, миграции и сложный рефакторинг Claude Opus 4.8 выигрывает у GPT-5.5 на SWE-bench (88.6% против 82.6%). Под terminal-задачи, написание тестов и CLI-утилит GPT-5.4 быстрее и дешевле. На повседневном кодинге разница в пределах 5-7%. Тестируй обе на своей задаче — бенчмарки не предсказывают результат для конкретного юзкейса.
Модели обучаются с задержкой 6-12 месяцев и часто не знают свежих API. Решение: вставляй в промпт фрагмент актуальной документации (50-100 строк со схемой запроса и форматом ответа). Так делают в API-интеграциях с Recurly, Stripe, любым нишевым сервисом. Чем свежее библиотека, тем больше доки в промпте.
Юридически да, если соблюдена лицензия инструмента. Claude, GPT, Gemini разрешают коммерческое использование сгенерированного кода. DeepSeek и Qwen открыты под MIT-лицензией. Практически: сгенерированный код требует ревью на безопасность и логику. Никогда не отправляй в промпт реальные токены, ключи API, персональные данные клиентов.
Промпт-инжиниринг — навык составления запросов к ИИ, при котором модель выдает максимально точный результат с минимума попыток. Включает работу с ролью, контекстом, форматом вывода.
SWE-bench Verified — индустриальный бенчмарк, в котором модель решает реальные issues из открытых GitHub-репозиториев. Цифра показывает процент успешно закрытых задач.
Контекстное окно — объем текста, который модель удерживает в одной сессии. В 2026 году стандарт 1M токенов (примерно 750 тысяч слов или 3000 страниц A4).
Plan Mode — режим в Claude Code, где модель сначала составляет план задачи, потом ждет подтверждения, и только потом пишет код. Снижает ошибки на 40-60% на многошаговых задачах.
Claude.md — постоянный файл-инструкция в корне проекта. Загружается в контекст автоматически при каждой сессии Claude Code. Хранит правила стиля, стек, конвенции.
Skills (навыки) — переиспользуемые наборы инструкций и инструментов в Claude Code. Один раз описал, дальше вызываешь через slash-команду. Подход Anthropic Engineers для повторяющихся задач.
MoE (Mixture of Experts) — архитектура моделей, где из общего числа параметров активируется только часть на каждый запрос. DeepSeek V4 Pro Max: 1.6T параметров суммарно, 49B активных. Дает качество большой модели по цене маленькой.
OpenRouter — агрегатор API доступа к 70+ моделям через единый интерфейс. Один ключ, один счет, любая модель. Удобно для тестирования и переключения под задачу.
Возьми 2-3 промпта из статьи и попробуй прямо сегодня на текущей задаче. Не пытайся использовать все 10 сразу — выбери те, что закроют ближайшую боль (тесты, отладка, рефакторинг). Через неделю практики результат начинает приходить со второй итерации вместо пятой.
Для постоянной работы стоит выбрать одну основную IDE с агентом: Claude Code, Cursor, Windsurf или Aider. Каждый подход в каталоге инструментов VibeCoderz разобран с ценами, плюсами и юзкейсами.
Если упираешься в выбор стека или формата работы с ИИ под конкретный продукт — запишись на консультацию к Максиму в Telegram. За час разбираем твою задачу, подбираем модель и собираем первую цепочку промптов под нее.
Статья обновлена: июнь 2026. Цены и бенчмарки моделей по данным OpenRouter, SWE-bench Leaderboard и официальной документации Anthropic, OpenAI, Google DeepMind, DeepSeek на 10 июня 2026.