Соберите данные с любого статического сайта за 30 минут, используя готовый промпт для Cursor/Windsurf и скрипт на requests, BeautifulSoup4 и pandas, который сразу экспортирует в CSV.
400 000+ органических переходов за 3 месяца. Со-основатель GoBanana (231K пользователей, 12+ млн ₽ без рекламы) и NeuroScribe (65K пользователей). SEO/GEO-стратегии для AI-поисковиков, 1 700+ единиц контента, 17+ реализованных стратегий.
Об авторе →Claude Code: новый CLI-агент от Anthropic
Anthropic выпустила Claude Code — терминальный AI-агент для разработчиков. Инструмент работает прямо в командной строке и умеет писать, редактировать и запускать код.
Zcode AI: Полный гид по визуальному интерфейсу для Claude Code и AI-агентов
Узнайте, как использовать Zcode для управления Claude Code, Gemini и Codex в едином GUI. Настройка провайдеров, MCP-серверов и визуальный вайбкодинг.
YouTube-канал с монетизацией из любой точки мира: Пошаговый гайд 2026
Инструкция по созданию YouTube-канала: обход блокировок SMS, настройка расширенных функций через виртуальные номера и правила безопасности для монетизации.
Windsurf Code Maps: Как глубоко понимать архитектуру проекта перед написанием кода
Полный гайд по Windsurf Code Maps, модели Sway 1.5 и Sway Grep. Узнайте, как визуализировать архитектуру кода и ускорить разработку в 13 раз.
Vk Fast Cash Strategy
Аудитория ВКонтакте — это те же люди, что и в Instagram, но 'социальный контракт' площадки другой. Если Instagram — это 'дорогой ресторан' с демонстрацией успеха, то VK — это 'душевная шашлычная'. Здесь не работает глянцевый 'успешный успех
Обновлено: июнь 2026
Парсер на Python сегодня пишут без единой строки кода вручную. Достаточно дать Cursor или Windsurf правильный промпт — и через 10 минут у вас рабочий скрипт, который собирает данные с любого статического сайта и экспортирует их в CSV.
В этой статье: готовый промпт для Cursor/Windsurf, стек requests + BeautifulSoup4 + pandas, обработка пагинации и типичные ошибки, которые гарантированно встретятся в первый раз.
Парсер сайта на Python через вайбкодинг — это реально за 30 минут. Стек: requests (HTTP-запросы) + BeautifulSoup4 (парсинг HTML) + pandas (экспорт в CSV). Промпт для Cursor занимает 10 строк, код — около 50. В статье: пошаговый промпт, готовый скрипт, разбор пагинации и частых ошибок.
Парсер нужен, когда у сайта нет API, данных слишком много для ручного копирования, или информация меняется и нужна автоматизация.
По сути, парсинг — это автоматизированное копирование данных с веб-страницы. Вручную вы открываете страницу, копируете цену, переходите на следующую. Парсер делает то же самое, но за 10 секунд для тысячи позиций.
Реальные задачи, под которые его пишут:
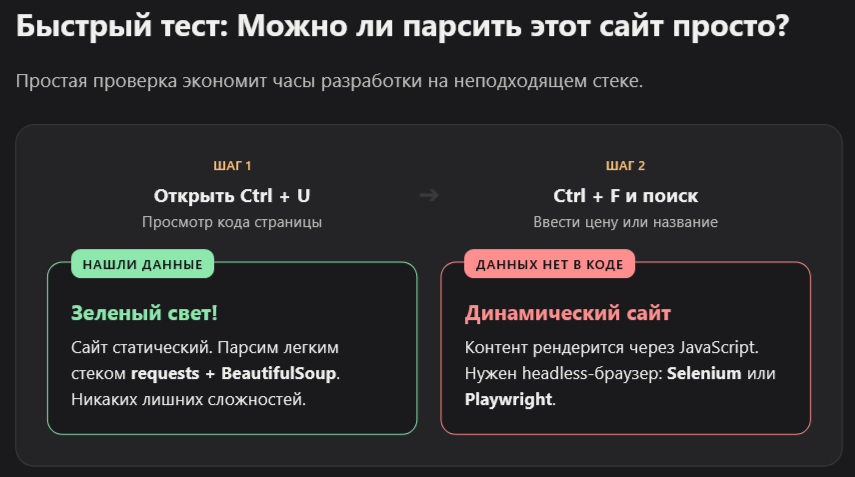
Но сначала — проверка. Не каждый сайт можно спарсить через requests.
Откройте View Source (Ctrl+U) и найдите нужные данные в исходном HTML. Если данные там есть — парсить можно через requests + BeautifulSoup. Если нет — сайт рендерит контент JavaScript-ом и нужен Selenium.
Это самый частый подводный камень для новичков. Смотришь на страницу — видишь цены. Запускаешь парсер — получаешь пустоту. Причина: сайт отдаёт «скелет» HTML, а данные подгружает отдельным JS-запросом.
Алгоритм проверки простой:
Для второго случая нужен Selenium или Playwright. Но для большинства товарных каталогов, агрегаторов и новостных сайтов requests работает без проблем.
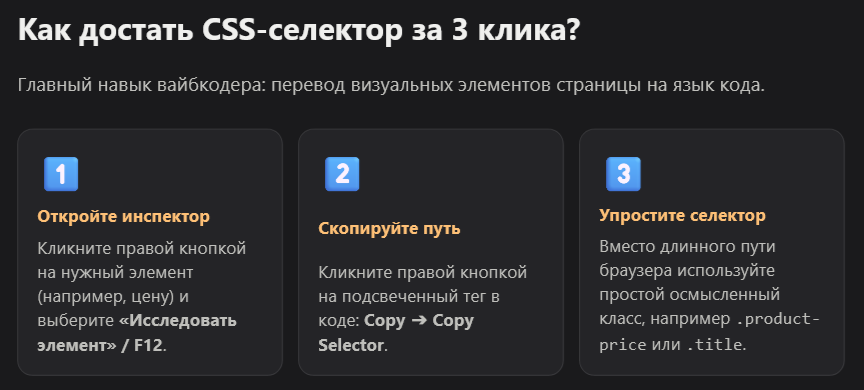
Правая кнопка на элементе -> Inspect -> правая кнопка на теге в DevTools -> Copy -> Copy selector. Это строка типа .product-card .price — она пойдёт прямо в промпт.
Открываете DevTools (F12), берёте инструмент выбора элемента (стрелочка в левом верхнем углу), кликаете на нужный элемент на странице. В панели Elements видите тег и его классы. Правая кнопка на теге — Copy — Copy selector.
Здесь есть нюанс. Браузер часто копирует длинный и нечитаемый селектор вроде #root > div > main > div:nth-child(3) > ul > li:nth-child(1) > span. Он работает, но хрупкий — сломается при малейшем изменении вёрстки. Лучше найти осмысленный класс, например .price или .product-name, и использовать его.
Если CSS-класс выглядит как генерированный — sc-abc123-title или что-то похожее — поищите родительский элемент с нормальным атрибутом data-* или id.
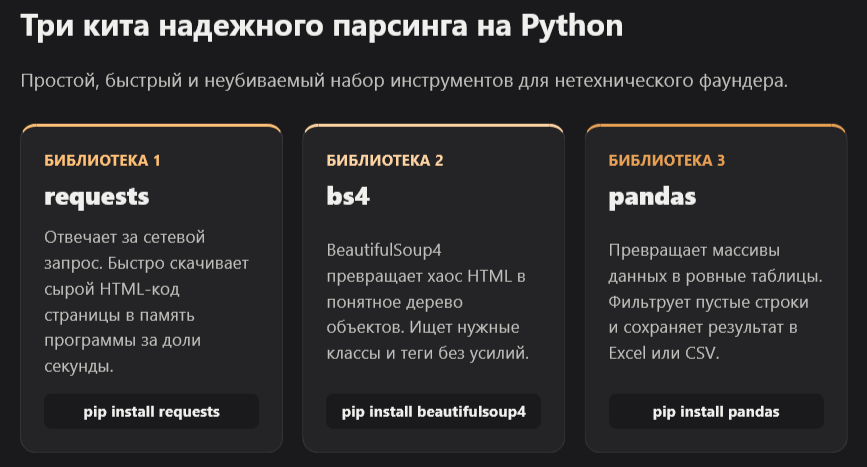
requests скачивает HTML страницы. BeautifulSoup4 разбирает этот HTML и находит нужные элементы по CSS-селекторам. pandas собирает все данные в таблицу и сохраняет в CSV. Три библиотеки, каждая делает одно.
| Библиотека | Задача | Установка |
|---|---|---|
| requests | HTTP-запрос к сайту | pip install requests |
| beautifulsoup4 | Парсинг HTML | pip install beautifulsoup4 |
| pandas | Экспорт в CSV/Excel | pip install pandas |
| lxml | Быстрый HTML-парсер (опционально) | pip install lxml |
Всё вместе: pip install requests beautifulsoup4 pandas lxml
Это стандартный стек для статических сайтов в 2026 году. Он простой, хорошо задокументированный, и AI-инструменты знают его отлично — промпты работают с первого раза.
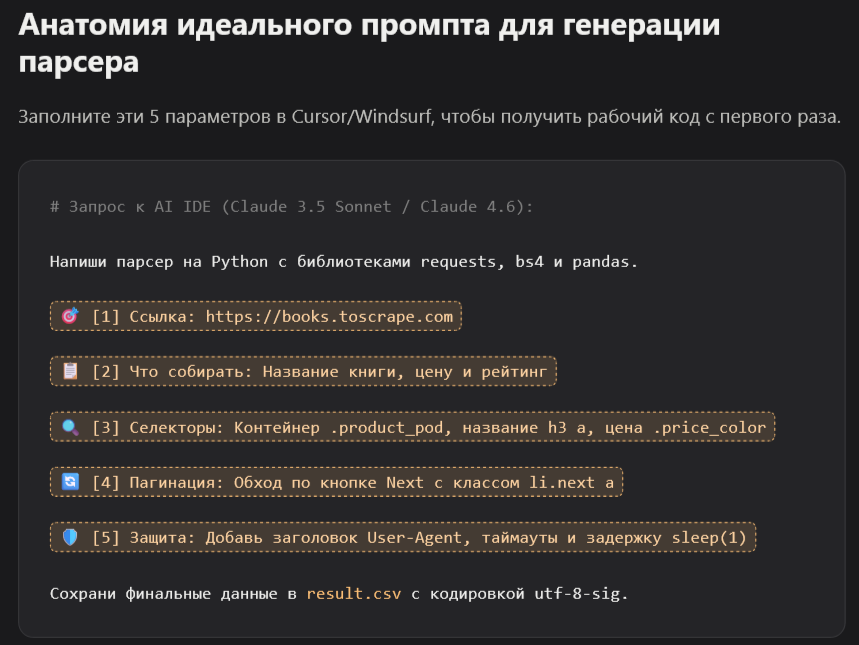
Вставьте этот промпт в чат Cursor (Ctrl+L) или Windsurf, укажите URL и CSS-селекторы — и получите рабочий скрипт за 1-2 минуты.
Промпт ниже — это то, с чего стоит начинать. Подставьте свои данные в скобках:
Промпт для Cursor:
Напиши парсер на Python используя библиотеки requests, beautifulsoup4 и pandas.
Задача:
- Парсить сайт: [URL сайта, например https://books.toscrape.com]
- Собрать данные: [что собирать, например название книги и цену]
- CSS-селекторы элементов: [например .product_pod h3 a для названия, .price_color для цены]
- Обработать пагинацию: [да/нет, если да — указать паттерн URL или найти кнопку next]
- Сохранить результат в: result.csv
Требования:
- Добавить заголовок User-Agent в запросы
- Обработать ошибки если элемент не найден (вернуть None)
- Добавить задержку 1 секунда между запросами
- Напечатать прогресс парсинга в консоль
Установка зависимостей: pip install requests beautifulsoup4 pandasЭтот промпт даёт AI весь нужный контекст. Cursor с Claude 3.5 или Claude Opus 4.6 генерирует рабочий код в 9 случаях из 10 без итераций.
Для Windsurf — тот же промпт, вставляйте в Cascade.
Скрипт ниже парсит любой статический сайт: делает GET-запрос, ищет элементы по CSS-селекторам, обрабатывает ошибки и сохраняет в CSV. Адаптируйте URL и селекторы под свою задачу.
Вот базовый шаблон, который генерирует Cursor по промпту выше. Разберём его по частям:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
BASE_URL = "https://books.toscrape.com/catalogue/"
def extract_text(html, selector):
"""Безопасное извлечение текста — возвращает None вместо ошибки."""
try:
return html.select_one(selector).text.strip()
except AttributeError:
return None
def parse_page(url):
"""Парсит одну страницу и возвращает список словарей."""
response = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(response.text, "lxml")
items = []
for product in soup.select(".product_pod"):
items.append({
"name": extract_text(product, "h3 a"),
"price": extract_text(product, ".price_color"),
"rating": product.select_one("p")["class"][1] if product.select_one("p") else None
})
return items
def get_next_page(soup, base_url):
"""Возвращает URL следующей страницы или None."""
next_btn = soup.select_one("li.next a")
if next_btn:
return base_url + next_btn["href"]
return None
def run_parser(start_url):
all_data = []
url = start_url
page_num = 1
while url:
print(f"Парсим страницу {page_num}: {url}")
response = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(response.text, "lxml")
all_data.extend(parse_page(url))
url = get_next_page(soup, BASE_URL)
page_num += 1
time.sleep(1) # задержка между запросами
return all_data
if __name__ == "__main__":
data = run_parser("https://books.toscrape.com/catalogue/page-1.html")
df = pd.DataFrame(data)
df.to_csv("result.csv", index=False, encoding="utf-8-sig")
print(f"Готово. Собрано {len(df)} записей -> result.csv")Этот скрипт обходит все страницы сайта books.toscrape.com (учебный ресурс для тренировки парсинга), собирает названия и цены книг, и сохраняет всё в CSV.
Для вашего сайта меняете три вещи: BASE_URL, селекторы внутри parse_page и логику поиска следующей страницы в get_next_page.
Найдите CSS-селекторы через DevTools, скопируйте их в промпт вместо примеров. Укажите точный URL страницы с данными и формат пагинации — Cursor сгенерирует готовый скрипт.
Разберём на реальном примере. Допустим, нужно парсить карточки товаров с ценами на каком-то магазине.
Шаг 1. Открываете страницу, F12, кликаете на название товара. Видите: <h2 class="product-title">Название товара</h2>. Ваш селектор: .product-title.
Шаг 2. Кликаете на цену. Видите: <span data-ui="sale-price">1 290 руб.</span>. Ваш селектор: [data-ui="sale-price"].
Шаг 3. Ищете пагинацию. Кнопка «Следующая» ведёт на /page/2 — значит паттерн ?page=2. Если есть кнопка с классом .next-page — укажите её в промпте.
Шаг 4. Вставляете в промпт:
- Парсить сайт: https://example-shop.ru/catalog
- Собрать: название (.product-title) и цену ([data-ui="sale-price"])
- Пагинация: URL паттерн /catalog?page=2, /catalog?page=3И всё. Cursor генерирует готовый скрипт.
Максим: «У меня был случай — нужно было собрать 3 000 товарных позиций с прайса конкурента. Написал в Cursor буквально: "напиши парсер для этого сайта, вот CSS-селекторы, сохрани в CSV". Получил рабочий код за 8 минут. Раньше такое занимало полдня и требовало разработчика. Вот такие пироги.»

Два подхода: URL с номером страницы (?page=2) или кнопка next в HTML. Cursor генерирует оба варианта по запросу — просто опишите что видите в DevTools.
Вариант А — числовая пагинация. URL меняется по паттерну: /products?page=1, /products?page=2. Самый простой случай.
Промпт-добавка: «Пагинация через URL параметр page, начинаем с page=1, заканчиваем когда страница вернет 0 товаров или статус 404».
Код:
for page in range(1, 100):
url = f"https://example.ru/catalog?page={page}"
items = parse_page(url)
if not items:
break
all_data.extend(items)
time.sleep(1)Вариант Б — кнопка Next. На странице есть кнопка с текстом «Следующая» или со стрелкой. BeautifulSoup ищет её и берёт ссылку href.
Это уже показано в коде выше — функция get_next_page. Cursor генерирует её автоматически, если написать: «добавь обход страниц через кнопку next с классом .pagination-next».
Три самые частые ошибки: AttributeError (элемент не найден), 403 (сайт блокирует), ConnectionError (таймаут). Каждую вставьте в чат Cursor — он исправит код за 30 секунд.
Ошибка 1: AttributeError: 'NoneType' object has no attribute 'text'
Это когда элемент на странице не найден. Решение — функция extract_text с try/except, которая уже есть в шаблоне выше. Cursor добавит её автоматически если написать: «обработай случай когда элемент не найден, вернуть None».
Ошибка 2: Статус 403 или 503
Сайт идентифицирует запрос как бота. Первый шаг — добавить реальный User-Agent из вашего браузера (введите «my user agent» в Google — скопируете строку). Второй шаг — добавить задержку между запросами. Если не помогает — нужны прокси.
Ошибка 3: ConnectionError / ReadTimeout
Добавьте timeout в requests.get: requests.get(url, headers=HEADERS, timeout=10). И оберните в try/except с повтором через 5 секунд.
Любую из этих ошибок просто вставляете в Cursor: «вот ошибка: [текст ошибки], исправь». Это работает лучше, чем самостоятельный поиск.

pandas.DataFrame(data).to_csv('result.csv') — одна строка кода. Для Excel: df.to_excel('result.xlsx', index=False). Encoding utf-8-sig нужен чтобы кириллица открывалась корректно в Excel.
import pandas as pd
data = [
{"name": "Товар 1", "price": "1290 руб."},
{"name": "Товар 2", "price": "890 руб."},
]
df = pd.DataFrame(data)
# CSV — открывается в любом редакторе
df.to_csv("result.csv", index=False, encoding="utf-8-sig")
# Excel — если нужен .xlsx
df.to_excel("result.xlsx", index=False, engine="openpyxl")
print(f"Готово: {len(df)} записей")utf-8-sig — важная деталь. Без неё кириллица в Excel превращается в кашу. С этим кодированием файл открывается нормально.
Если хотите добавить фильтрацию или сортировку — спросите Cursor: «отфильтруй строки где price не None и отсортируй по price по возрастанию».
Оба справляются. Cursor удобнее для итеративной отладки через Ctrl+L прямо в файле. Windsurf экономичнее по токенам. Для первого парсера — не критично, берите тот который уже стоит.
Небольшое сравнение по практике:
| Критерий | Cursor | Windsurf |
|---|---|---|
| Контекст файла при вопросах | Ctrl+L — AI видит весь файл | Cascade — аналогично |
| Объяснение кода | Спросите через Ctrl+L | Спросите в Cascade |
| Расход токенов | Выше | Ниже |
| Отладка ошибок | Вставьте traceback в чат | Вставьте traceback в чат |
| Модели | Claude Opus 4.6, GPT-4o | Claude Sonnet 4.6 по умолчанию |
Из транскрипций видео с практиками: Cursor лучше для обучения — он объясняет что делает каждая часть кода, если спросить. Это важно для первого парсера, когда хочется понять логику, а не только получить рабочий скрипт.
Для Cursor есть конкретный лайфхак из видео: если сгенерированный код непонятен, спросите прямо в чате «объясни переменную X» или «почему используется enumerate». AI объяснит без лишних слов.

Crawl4AI — открытая библиотека, которая конвертирует HTML в чистый Markdown перед передачей в LLM. Удобна если парсите страницы для последующей обработки AI. Для простого сбора данных в CSV — BeautifulSoup проще и надёжнее.
Crawl4AI появилась как инструмент для задач с AI-обработкой контента. Суть: библиотека сначала парсит страницу, затем очищает HTML от мусора и возвращает структурированный Markdown. Это удобно когда следующий шаг — отдать контент в ChatGPT или Claude для генерации описаний.
Если ваша задача — собрать таблицу цен или список товаров в CSV, BeautifulSoup + requests по-прежнему проще и понятнее. Меньше зависимостей, больше контроля над тем что именно вы извлекаете.
Для новичков рекомендация: начните с requests + BeautifulSoup. Когда поймёте логику парсинга — добавите Crawl4AI или Playwright по необходимости.
Обзоры инструментов для вайбкодинга, включая Cursor и Windsurf, смотрите в нашем каталоге. Все актуальные AI IDE — на странице vibecoderz.ru/ide.
Если раньше написать парсер казалось задачей «только для программистов» — это уже не так. Схема простая:
python parser.pyДля первого раза берите учебный сайт books.toscrape.com — он создан специально для практики парсинга, не блокирует запросы и имеет удобную пагинацию.
После первого рабочего парсера адаптировать под реальные задачи — вопрос ещё одного промпта.
Если хотите разобраться глубже или нужна помощь с конкретной задачей — запишитесь на консультацию к Максиму. Весь каталог AI-инструментов для вайбкодинга — на нашем сайте.
Можно ли написать парсер на Python без знания кода?
Да. Через Cursor или Windsurf достаточно описать задачу текстом: какой сайт, что собрать, куда сохранить. AI сгенерирует рабочий скрипт на requests + BeautifulSoup. Нужно понимать структуру HTML и уметь открыть терминал.
Какой стек выбрать для парсера-новичка в 2026 году?
Для статических сайтов: requests + BeautifulSoup4 + pandas. Это самый простой и надёжный вариант. Для сайтов с JavaScript нужен Selenium или Playwright — чуть сложнее, но AI справляется и с ними.
Как проверить, можно ли парсить сайт?
Откройте инспектор (F12), найдите нужный элемент. Если данные есть в исходном HTML при View Source — парсить можно через requests. Если данных нет — сайт рендерит контент через JavaScript, нужен headless-браузер.
Что делать если парсер получает ошибку 403 или 503?
Добавьте заголовок User-Agent в запрос — это первый шаг. Если не помогает, добавьте задержку между запросами через time.sleep. При систематических блокировках нужны прокси.
Как парсить несколько страниц с пагинацией?
В промпте для Cursor укажите: «добавь цикл для перехода по страницам». BeautifulSoup ищет кнопку next или формирует URL вида /page/2, /page/3. Код получается в 10-15 строк.
Как сохранить данные парсера в Excel или CSV?
Через библиотеку pandas: df = pd.DataFrame(data) -> df.to_csv('result.csv', index=False). В Cursor достаточно написать в чате: «сохрани результат в CSV через pandas с кодировкой utf-8-sig».
Cursor или Windsurf — что лучше для написания парсера?
Оба работают. Cursor удобнее для итеративной отладки через Ctrl+L в файле. Windsurf экономичнее по токенам. Для парсера-новичка разница незначительная — берите тот, которым уже пользуетесь.
Парсинг (web scraping) — автоматическое извлечение данных с веб-страниц. Программа имитирует браузер: запрашивает страницу, получает HTML, извлекает нужные данные.
requests — Python-библиотека для HTTP-запросов. Отправляет GET/POST запросы к серверу и возвращает ответ (обычно HTML).
BeautifulSoup4 (bs4) — библиотека для парсинга HTML и XML. Преобразует строку HTML в объектную модель, по которой можно делать поиск через CSS-селекторы или теги.
CSS-селектор — правило для выбора HTML-элементов. Например, .price находит все элементы с классом price, #main — элемент с id="main", [data-type="sale"] — элемент с атрибутом data-type равным sale.
pandas — библиотека для работы с табличными данными. Используется для сборки данных в DataFrame и экспорта в CSV или Excel.
User-Agent — строка в HTTP-заголовке, которая идентифицирует «браузер» делающий запрос. Без неё некоторые сайты отклоняют запросы как ботов.
Пагинация — разбивка контента на страницы. Парсер должен обходить все страницы последовательно.
Статический сайт — сайт, где данные находятся прямо в HTML-ответе сервера. Парсится через requests + BeautifulSoup.
Динамический сайт — сайт, где данные загружаются через JavaScript после первоначального HTML. Требует headless-браузера: Selenium или Playwright.
headless-браузер — браузер без графического интерфейса. Запускается в фоне, исполняет JavaScript и возвращает финальный HTML с загруженными данными.
lxml — быстрый HTML/XML парсер на C. Используется как движок для BeautifulSoup: BeautifulSoup(html, "lxml") работает быстрее чем "html.parser".
Обновлено: июнь 2026 | VibeCoderz — база знаний по вайбкодингу и AI IDE