Hermes Agent не привязан ни к одному провайдеру. Он работает с OpenRouter, Anthropic, OpenAI, Nvidia, локальными моделями через Ollama, LM Studio и любым OpenAI-совместимым endpoint. Переключение между ними занимает 30 секунд.
10+ лет в маркетинге, 300+ клиентских проектов: сайты, реклама, боты. Создатель GoBanana (228K+ пользователей, 11.6 млн ₽ выручки) и VibeCoderz. Делаю AI-продукты сам через Claude Code, Cursor, Windsurf и консультирую тех, кто хочет так же.
Об авторе →Бесплатная нейросеть для кода: 7 вариантов которые реально работают в 2026
Бесплатная нейросеть для кода в 2026 году превратилась из урезанной демки в полноценный инструмент. DeepSeek работает из России без VPN. Gemini Code Assist дает 6000 запросов в день бесплатно. Continue + Ollama это полностью локальный аналог Copilot…
Google AI IDE в 2026 Gemini Code Assist Cloud Shell и Gemini CLI — что выбрать
Google предлагает три разных инструмента для AI-разработки. Gemini Code Assist — бесплатный плагин для VS Code и JetBrains с 6000 запросами кода в день. Gemini CLI — терминальный агент с 1 миллионом токенов контекста и открытым кодом под Apache 2.0.…
Hermes Agent: полный список CLI-команд и шпаргалка по использованию 2026
Hermes Agent управляется из командной строки. Агент, который вы хотите запустить, настроить, обновить или переключить на другую модель — всё делается через hermes и производные команды. Эта статья — полная шпаргалка: что делает каждая команда, когда…
Hermes Agent vs OpenClaw: честное сравнение двух главных open-source агентов 2026
Hermes Agent набрал 128 000 звезд на GitHub за 10 недель. OpenClaw стоит на отметке 345 000 и продолжает расти. Оба — open-source, оба работают с Telegram и Claude, оба выполняют реальные задачи на реальных компьютерах.
Hermes Agent и Telegram: как подключить агента к мессенджеру и управлять им с телефона
После установки Hermes работает в терминале — вы можете общаться с ним только сидя за компьютером. Telegram меняет это: агент появляется в мессенджере, отвечает на сообщения с телефона и выполняет задачи, пока вы не у экрана.
Hermes Agent Skills: как работают навыки и где взять 150+ готовых для своего агента
Skills — это то, что отличает Hermes от обычного AI-агента. Навык (skill) — сохранённый рецепт: пошаговая инструкция, которую агент написал себе сам после выполнения сложной задачи. Следующий раз при похожем запросе он не думает с нуля — загружает на…
Hermes Agent не привязан ни к одному провайдеру. Он работает с OpenRouter, Anthropic, OpenAI, Nvidia, локальными моделями через Ollama, LM Studio и любым OpenAI-совместимым endpoint. Переключение между ними занимает 30 секунд.
В этой статье: как устроена архитектура «мозг снаружи», какой провайдер подходит для каких задач, точные команды для настройки каждого варианта и что делать, если хочется работать бесплатно или без передачи данных за рубеж.

Hermes — это не модель. Это оболочка: агентский цикл, инструменты, память, навыки. Модель — внешний мозг, который принимает решения. Hermes выполняет то, что модель решила сделать.
Это разделение принципиально. Одна и та же задача на Claude Opus 4.7 и на бесплатной модели через OpenRouter даёт принципиально разное качество. Не потому что Hermes хуже — просто мозг другой.
Из этого следует практическое правило: чем сложнее и длиннее задача, тем важнее качество модели. Для ежедневного дайджеста новостей GPT-5.4 mini отлично справляется. Для отладки 500 строк кода DeepSeek V4 Pro или Claude Opus 4.7 дадут результат на порядок лучше.
Лиза: «Мы гоняли Hermes на разных моделях для задач контент-автоматизации NanaBanana. GPT-5.4 mini хватает для сбора и форматирования данных — стоит копейки. На DeepSeek V3.2 через OpenRouter переходим только когда нужно анализировать большие объёмы или генерировать тексты. Разница в расходах — в 15-20 раз.»
Есть одно жёсткое техническое требование: контекстное окно модели должно быть минимум 64k токенов. Меньше — агент начнёт терять данные при многошаговых задачах. Не потому что ограничение Hermes, а потому что агентские цепочки инструментов быстро забивают контекст.

Независимо от провайдера, переключение модели всегда делается одной командой:
hermes modelОткрывается интерактивное меню. Стрелками выбираете провайдера, потом модель. Изменение применяется немедленно, без перезапуска агента и без правки конфигурационных файлов.

Внутри активного чата переключение делается slash-командой:
/modelЭто не прерывает текущую сессию — агент переключает «мозг» на лету. Именно этого не умеет большинство конкурентов: при смене модели в OpenClaw сессия ломается.
OpenRouter — агрегатор API. Один аккаунт, один ключ, доступ ко всем ведущим моделям: Claude, GPT, Gemini, DeepSeek, Grok, Qwen, Llama и сотни других. Провайдер автоматически роутит запросы.
Основная практическая причина — переключение моделей без смены API-ключа. Хочется попробовать DeepSeek V4 Pro вместо GPT-5.4 mini — просто меняете строку модели, ключ остаётся тот же. Не нужно заходить в пять разных личных кабинетов.
Второй плюс — OpenRouter Auto. Специальный режим, в котором OpenRouter сам выбирает модель под тип запроса: дешёвая для рутинных задач, дорогая для сложных. На практике это работает: простые запросы идут на Gemini 2.5 Flash или GPT-5.4 Nano, тяжёлые рассуждения — на Claude Opus. Итоговый счёт заметно ниже, чем при постоянном использовании топовых моделей.
Регистрируетесь на openrouter.ai, добавляете кредиты (минимум $5-10 для старта), создаёте API-ключ. Рекомендуется установить кредитный лимит — например, $25-50 в месяц — чтобы случайный сбой агента не опустошил счёт.
В Hermes:
hermes model
# В меню выберите: OpenRouter
# Введите API-ключ
# Выберите модель или введите custom model nameДля режима Auto введите имя модели как openrouter/auto.
| Модель | Тип | Стоимость | Для чего |
|---|---|---|---|
| openrouter/auto | Авто-роутинг | Смешанная | Повседневные задачи |
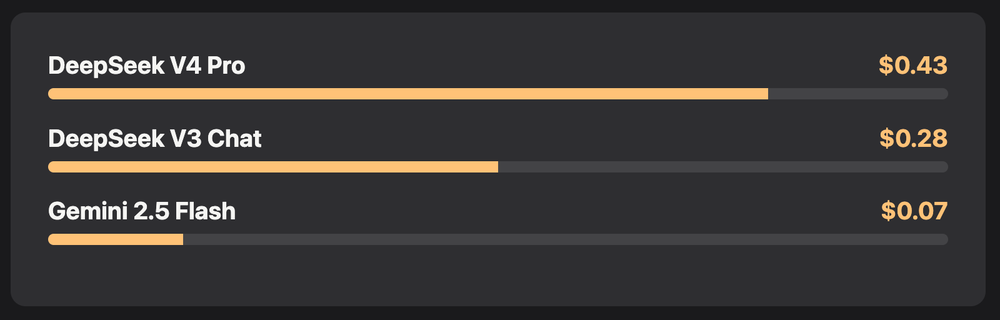
| deepseek/deepseek-chat-v3 | Платная | $0.28/M input | Кодинг, анализ |
| deepseek/deepseek-v4-pro | Платная | $0.43/M input | Сложный кодинг, большие файлы |
| google/gemini-2.5-flash | Платная (дёшево) | ~$0.075/M input | Быстрые рутинные задачи |
| minimax/minimax-m2.5 | Бесплатная | $0 | Тестирование, лёгкие задачи |
| nvidia/llama-3.1-nemotron-70b | Бесплатная | $0 | Бесплатный тест |
Если используете OpenRouter Auto, в настройках роутинга укажите именно те модели, к которым хотите ограничить доступ. Дорогие модели вроде Claude Opus 4.7 могут съедать $10+ за 10 запросов на сложных задачах. Для старта безопаснее ограничить три:
Потом расширяете по мере понимания своих сценариев.
OpenRouter предоставляет несколько моделей полностью бесплатно. Есть рейт-лимиты по запросам в час, доступность может меняться, но для тестирования и лёгкой нагрузки работает.
Актуальные бесплатные варианты на май 2026:
Для получения бесплатного доступа нужно пополнить счёт хотя бы на $1 — это активирует аккаунт. После этого бесплатные модели работают без списания.
Чтобы выбрать бесплатную модель, которой нет в стандартном меню Hermes, выберите «Enter custom model name» и вставьте идентификатор из карточки модели на openrouter.ai.
Важно: бесплатные модели подходят для знакомства с Hermes. Для серьёзных агентских задач — кодинга, анализа, автоматизации сложных workflows — разница с платными моделями существенная. Это не недостаток Hermes, это математика: более мощный мозг даёт лучший результат.
Для работы из России проблема OpenRouter, Anthropic и OpenAI — блокировки и сложности с оплатой. Nvidia NIM решает часть этой проблемы.

Nvidia предоставляет OpenAI-совместимый API через программу для разработчиков. Доступ бесплатный, достаточно зарегистрироваться на build.nvidia.com. Доступна модель MiniMax M2.7 с контекстным окном 1M токенов — полностью бесплатно.
Настройка в Hermes как кастомного endpoint:
hermes model
# Выберите: Custom OpenAI-compatible endpoint
# Base URL: https://integrate.api.nvidia.com/v1
# API Key: ваш ключ с build.nvidia.com
# Model name: nvidia/minimax-m2.7Это не ограниченная бета — ключ выдаётся сразу после регистрации, работает стабильно.
Ollama запускает open-source модели на вашем железе. Никаких API-ключей, никаких облачных серверов, никакой ежемесячной платы. Данные не покидают машину.
Это важно в двух сценариях: когда у вас чувствительные данные (медицина, финансы, юриспруденция) или когда просто хотите контролировать расходы при высокой нагрузке.
Минимальные требования зависят от модели. Для агентских задач нужна модель, которая умеет работать с инструментами (tool calling). Не каждая локальная модель это умеет — это ограничение самих моделей, не Hermes.
Рекомендованные модели для локального запуска:
| Модель | VRAM | Tool calling | Для чего |
|---|---|---|---|
| GLM 4.7 Flash | 25 GB | Хорошо | Общие агентские задачи |
| Qwen 2.5 Coder 32B | 20 GB | Хорошо | Кодинг |
| Llama 3.1 70B | 40+ GB | Удовлетворительно | Общее назначение |
| Qwen 3.5 | 10-16 GB | Хорошо | Компромисс VRAM/качество |
| Gemma 4 | 12 GB | Хорошо | Быстрые задачи |

Если производительность локальной модели разочаровала — сначала попробуйте другую модель. Разные модели ведут себя очень по-разному в агентском режиме.
# Установка (Linux/macOS)
curl -fsSL https://ollama.ai/install.sh | sh
# Запуск как фоновый сервис
nohup ollama serve > /dev/null 2>&1 &
# Загрузка модели (пример)
ollama pull glm4:flashПроверьте, что Ollama работает:
ollama listhermes model
# Выберите: Custom OpenAI-compatible endpoint
# Base URL: http://127.0.0.1:11434/v1
# API Key: (оставьте пустым или введите любое слово — Ollama не требует ключ)
# Model name: glm4:flash (точно как указано в ollama list)Критически важно: Ollama по умолчанию использует маленький контекст. Для агентской работы нужно минимум 16k-32k токенов. Настройте это на стороне Ollama:
OLLAMA_NUM_CTX=32768 ollama serveИли при запуске конкретной модели:
ollama run glm4:flash --num-ctx 32768Без этой настройки агент будет терять контекст на длинных задачах.
LM Studio — это Ollama с удобным GUI. Подходит тем, кто не хочет разбираться с командной строкой для управления локальными моделями.
Принцип работы тот же: LM Studio поднимает локальный сервер, совместимый с OpenAI API. Hermes подключается к нему как к кастомному endpoint.
В LM Studio: откройте раздел «Server», включите сервер (порт по умолчанию 1234), загрузите модель.
В Hermes:
hermes model
# Выберите: Custom OpenAI-compatible endpoint
# Base URL: http://localhost:1234/v1
# API Key: (пустое или любое значение)
# Model name: имя модели точно как в LM Studio| Параметр | Ollama | LM Studio |
|---|---|---|
| Интерфейс | Командная строка | Графический |
| Автозапуск как сервис | Легко через systemd | Нужно держать открытым |
| Производительность | Одинаковая | Одинаковая |
| Управление моделями | CLI | GUI |
| VPS/сервер | Да | Нет (только десктоп) |
Для VPS и постоянной работы — Ollama. Для десктопного использования с визуальным управлением — LM Studio.

Если хотите работать с Claude напрямую, минуя OpenRouter, Hermes поддерживает нативный Anthropic API.
Преимущество нативного подключения: Hermes использует автоматическое кеширование промптов Anthropic. Системный промпт кешируется на всю сессию — каждый следующий запрос переиспользует кеш. Экономия около 75% на input-токенах при длинных многоходовых разговорах.

hermes model
# Выберите: Anthropic
# Введите API-ключ с console.anthropic.com
# Выберите модель: Claude Sonnet 4.6 или Claude Opus 4.7Модели от дешёвой к дорогой:
Про Россию: прямой доступ к Anthropic API из России ограничен — нужен VPN или VPS за рубежом. Через OpenRouter ситуация проще, т.к. запросы идут через инфраструктуру OpenRouter.
Hermes поддерживает OpenAI API нативно. Настройка аналогична — выбираете провайдер OpenAI, вставляете ключ.
DeepSeek имеет собственный OpenAI-совместимый API. Подключается как кастомный endpoint:
hermes model
# Выберите: Custom OpenAI-compatible endpoint
# Base URL: https://api.deepseek.com/v1
# API Key: ваш ключ с platform.deepseek.com
# Model name: deepseek-chat (V3) или deepseek-coderDeepSeek V4 Pro через их прямой API обходится дешевле, чем через OpenRouter — $0.43/M input токенов против немного выше через посредника. Для высоких объёмов разница ощутима.

| Сценарий | Рекомендация | Причина |
|---|---|---|
| Хочу попробовать Hermes бесплатно | OpenRouter (бесплатный тир) или Nvidia NIM | Нулевые расходы |
| Ежедневная автоматизация, нет чувствительных данных | OpenRouter Auto | Экономия + гибкость моделей |
| Кодинг и отладка | DeepSeek V4 Pro через OpenRouter или напрямую | Лучшее соотношение цена/качество для кода |
| Сложные многошаговые задачи | Claude Sonnet 4.6 / Opus 4.7 | Лучшие рассуждения и следование инструкциям |
| Чувствительные данные (медицина, финансы) | Ollama + GLM 4.7 Flash или Qwen 3.5 | Данные не покидают железо |
| Работа из России без VPN | Nvidia NIM + MiniMax M2.7 | Доступно напрямую |
| VPS 24/7 + экономия | OpenRouter Auto с лимитом $25/мес | Авто-роутинг на дешёвые модели |
| Максимальное качество ответов | Claude Opus 4.7 (нативно или через OpenRouter) | Лучший агентский LLM |
Это практически важный раздел, который часто обходят стороной.
OpenRouter — принимает карты Visa/Mastercard российских банков. Не всегда, зависит от эмитента. Если не проходит обычная карта, попробуйте виртуальную карту через сервисы типа Revolut, Wise или криптовалютное пополнение.
Nvidia NIM — регистрация через email, без платёжных данных для бесплатного тира. Самый простой способ начать.
Anthropic и OpenAI — прямая оплата из России заблокирована. Варианты: VPN + иностранная карта, или работать через OpenRouter как прокси.
DeepSeek — китайский сервис, принимает WeChat Pay и Alipay. Для российских карт ситуация нестабильная — лучше через OpenRouter.
Ollama и LM Studio — полностью бесплатны, ничего не нужно.
Несколько полезных команд, которые упрощают работу с разными моделями:
/model — интерактивное меню смены модели
/model deepseek — быстрое переключение, если знаете имя
/reasoning low — снизить глубину рассуждений (экономит токены на простых задачах)
/reasoning high — максимальная глубина для сложных задач
/usage — текущий расход токенов и лимитыУмная маршрутизация в Hermes: если задача сформулирована как простой вопрос, агент может сам переключиться на более дешёвую модель (при настроенном auto-routing в OpenRouter). При сложном кодинге — эскалирует на мощную модель.
Можно ли использовать Hermes Agent совсем бесплатно? Да. Два пути: OpenRouter с бесплатными моделями (Minimax M2.5, Nemotron) или Ollama с локальными моделями. В обоих случаях сам Hermes бесплатен, платите только за мощное железо или пополнение OpenRouter на $1 для активации.
Какая модель лучше всего работает с Hermes? Нет универсального ответа. Claude Sonnet 4.6 и Claude Opus 4.7 дают лучшее следование инструкциям и наименьший процент ошибок при агентских задачах. DeepSeek V4 Pro — отличный выбор для кодинга по соотношению цена/качество. Для локального запуска — GLM 4.7 Flash или Qwen 3.5.
Hermes agent API key — где взять? Это не ключ самого Hermes (агент бесплатный и ключей не требует). Ключ нужен для выбранного вами LLM-провайдера: OpenRouter на openrouter.ai, Anthropic на console.anthropic.com, Nvidia на build.nvidia.com. Ollama ключей не требует.
Работает ли LM Studio с Hermes на Windows? Да. LM Studio запускается нативно на Windows, поднимает локальный API-сервер. Hermes подключается к нему через WSL2, указывая адрес хост-машины Windows: http://host.docker.internal:1234/v1 или ip-адрес вашей Windows-машины.
Насколько дорого обходится Hermes при активном использовании? Зависит от модели. На Claude Opus 4.7 при нескольких сложных задачах в день — $30-100/месяц. На GPT-5.4 mini — $5-20/месяц. На DeepSeek V3.2 — $3-10/месяц. На OpenRouter Auto с бюджетными моделями — $1-5/месяц. Всегда устанавливайте кредитный лимит в OpenRouter.
Что значит контекстное окно 64k? Почему это важно? Контекстное окно — сколько текста модель держит «в уме» за одну задачу. Hermes при агентской работе генерирует длинные цепочки вызовов инструментов, истории разговоров, результаты. Модель с 8k контекста просто не вместит всё это и начнёт «забывать» начало задачи. 64k — минимальный комфортный размер. У Claude — 200k, у MiniMax M2.7 через Nvidia NIM — 1M.
Можно ли подключить к Hermes мою корпоративную LLM? Да. Если корпоративная LLM предоставляет OpenAI-совместимый API endpoint — укажите его как кастомный endpoint в настройках. Base URL, API-ключ (если требуется), имя модели.
OpenRouter — агрегатор API для языковых моделей. Один ключ дает доступ к сотням моделей от разных провайдеров.
OpenRouter Auto — режим автоматической маршрутизации запросов к оптимальной модели по соотношению цена/задача.
Ollama — инструмент для запуска open-source языковых моделей локально на собственном железе.
LM Studio — приложение с графическим интерфейсом для загрузки и запуска локальных моделей. Аналог Ollama для тех, кто предпочитает GUI.
Nvidia NIM — программа Nvidia для разработчиков с бесплатным доступом к API языковых моделей, размещённых на инфраструктуре Nvidia.
Custom OpenAI-compatible endpoint — настройка в Hermes, позволяющая подключить любой сервер, совместимый с форматом API OpenAI. Используется для Ollama, LM Studio, DeepSeek, корпоративных LLM.
Tool calling — способность модели вызывать внешние инструменты (браузер, терминал, файлы). Не все локальные модели поддерживают это надёжно.
Контекстное окно — максимальный объём текста, который модель обрабатывает за один запрос. Для Hermes нужно минимум 64k токенов.
Prompt caching — кеширование системного промпта Anthropic. Повторные запросы в одной сессии переиспользуют кеш, экономя ~75% на input-токенах.
hermes model — команда Hermes для интерактивного переключения провайдера и модели.
Полный обзор Hermes Agent — в нашей статье про возможности и архитектуру. Сравнение с OpenClaw — здесь. Другие AI-инструменты и IDE — в каталоге VibeCoderz.
Если хотите разобраться, какая конфигурация моделей подойдёт под ваши задачи и бюджет, запишитесь на консультацию к Максиму.
Обновлено: май 2026