Обновлено: июнь 2026
Универсальной модели для кодинга в 2026 году нет, и попытка решить все задачи одной нейросетью — основная причина, по которой счета за токены растут, а скорость падает. Лучший ИИ для программирования зависит от того, что вы сейчас делаете: сложный рефакторинг → Claude Opus 4.8, работа агента в терминале → GPT-5.5, фронтенд и UI → Qwen3.7 Max или Gemini 3.1 Pro, массовые однотипные задачи → DeepSeek V4 Flash. Ниже разберем каждую задачу с цифрами, ценами и связками моделей, которые реально работают в проде.

TL;DR. На июнь 2026 рынок ИИ для программирования закрыт четырьмя моделями под разные задачи. Claude Opus 4.8 берет рефакторинг (88.6% SWE-bench Verified). GPT-5.5 лидирует в терминале (82.7% Terminal-Bench, #1). Qwen3.7 Max дает 80.4% SWE-bench за $1.25/$3.75. DeepSeek V4 Flash тянет bulk за $0.14/$0.28. В статье — таблица, связки и карта выбора.
Почему одна модель не справляется со всеми задачами в программировании?
Каждая модель обучена на своем датасете, поэтому сильна в одной зоне и слабее в других. Универсальная нейросеть для кодинга на практике проигрывает связке из 3-4 специализированных.
Между релизами Claude Opus 4.8 и GPT-5.5 разрыв на SWE-bench Verified — 6 процентных пунктов (88.6% против 82.6%), но на Terminal-Bench 2.0 ситуация обратная: GPT-5.5 берет 82.7% и держит первое место. На рефакторинге выигрывает Opus, на агентах в терминале — GPT. Это не маркетинг, а разное обучение.

Старая привычка из 2024 года — поставить одну подписку, например Cursor + Claude, и закрыть все вопросы. На рынке 2026 года это стоит дороже и работает медленнее, чем подбирать модель под задачу.
Корбин Браун в свежем разборе на YouTube (The Best Model For AI Coding Is...) сформулировал короткое правило. GPT — планировщик (медленный, но дает архитектурно чистые планы). Opus — исполнитель кода по плану. Gemini — полировщик UI. И ни одна из трех не делает работу за двух остальных хорошо.
Дальше разберем каждую задачу отдельно: что брать, сколько это стоит и где модель проседает.
Какой ИИ выбрать для сложного рефакторинга и архитектуры?
Для рефакторинга многофайловых проектов и архитектурных решений в 2026 году берите Claude Opus 4.8. SWE-bench Verified — 88.6%, второе место после Mythos-класса.
Opus 4.8 решает 88.6% задач SWE-bench Verified, занимает первое место в AA Intelligence Index с показателем 61.4, контекстное окно — 1M токенов. Цена — $5 за миллион входных и $25 за миллион выходных токенов. Фишка релиза мая 2026 года — Dynamic Workflows с поддержкой до 1000 параллельных субагентов. Это и есть рабочий инструмент для рефакторинга.

Где Opus реально вытаскивает. Рефакторинг большого PHP-монолита, разнесение дублирующейся логики по общим модулям, миграция сервиса с одной библиотеки на другую с сохранением интерфейсов. В тесте на 28 файлах с тонким багом Opus 4.6 уже обошел GPT-5.2 на 144 ELO в knowledge work задачах. Версия 4.8 — это апгрейд за те же деньги.
Где проседает. Скорость. Реальный кейс из теста на E2E-баге: Opus решал за 13 минут, Qwen 3.5 Plus — за 9, GPT-5.3 Codex — за 3 минуты. Если нужно гонять много мелких правок, Opus дороже и медленнее по чистому времени.
Связка под рефакторинг: Opus 4.8 в Claude Code или Cursor c режимом thinking, обязательный git commit перед каждой большой итерацией.
Что использовать для работы в терминале и автономных агентов?
Для агентских задач в терминале и автономных пайплайнов в июне 2026 года выбирайте GPT-5.5. Terminal-Bench 2.0 — 82.7%, первое место.
GPT-5.5 от OpenAI на Terminal-Bench 2.0 показывает 82.7% и опережает Opus 4.8 в задачах с длинным горизонтом действий, где модель сама запускает команды, читает вывод, корректирует подход. Цена — $5/$30 за миллион токенов, контекст 1.05M. В xHigh reasoning mode pass@1 растет на 6.2 п.п., но стоимость удваивается.
Где GPT-5.5 закрывает зону, в которой Opus проседает. Триаж тикетов в фоне через Codex App, ежедневные отчеты по CI, debug-петли с самокоррекцией. На реальном E2E-баге, который воспроизводился только через браузер, GPT-5.3 Codex закрыл задачу за 3 минуты против 13 у Opus. На длинных автономных задачах разрыв сохраняется.
И отдельно про планирование. В разборах Корбина Брауна и других вайбкодеров GPT берут именно как планировщика — он медленный, но дает архитектурно чистые планы, которые потом исполняет Opus.

Где не подойдет. Чистый UI и красивый фронтенд — это не сильная сторона GPT. На дизайнерских задачах он отдает корректный, но скучный код.
Какая нейросеть лучше для фронтенда и UI?
Для фронтенда и красивого интерфейса в 2026 году две рабочих опции: Qwen3.7 Max ($1.25/$3.75) или Gemini 3.1 Pro ($2/$12). За 1/6 цены Opus вы получаете 80% его качества на UI-задачах.
Qwen3.7 Max от Alibaba вышел в июне 2026, дает 80.4% SWE-bench Verified и 60.6% SWE-bench Pro (vendor harness). Цена — $1.25 за миллион входных и $3.75 за выходных. По выходным токенам это в 6.67 раза дешевле Opus 4.8. Аналитики называют его «рациональной альтернативой Opus 4.8».
Что важно понимать про фронтенд и нейросети. На задачах вида «сделай красивый дашборд с анимациями, hover-эффектами и плавными переходами» Opus и GPT часто выдают рабочий, но скучный код. Gemini 3.1 Pro и Qwen3.7 Max в этом сегменте обходят их за счет другого обучения — больше визуального контекста и фронт-фреймворков в датасете.
Реальный кейс из практики Корбина: финальная полировка интерфейса Thumio (его собственный проект) шла через Gemini 3.1. Hover-эффекты, бесконечная прокрутка, интерактивные пилюли — все это код от Gemini. Логику кликов и переходов писал Opus.

Где минусы Gemini. Он непредсказуем. На одной итерации дает блестящий результат, на другой уходит в петлю и переписывает половину файлов. Обязательный git commit перед каждым вызовом — не лайфхак, а гигиена.
Какой ИИ для программирования взять при бюджете в копейки?
Для bulk-задач и экспериментов в 2026 году самый дешевый сильный кодер — DeepSeek V4 Flash. Цена $0.14/$0.28, лицензия MIT, можно self-host. SWE-bench около 79%.
DeepSeek V4 Flash держит первое место по использованию в OpenRouter Programming Collection. Архитектура MoE: 284B параметров total, 13B активных. Контекст 1M на вход, 384K на выход. Лицензия MIT означает, что вы можете развернуть модель на своем железе и не платить вообще ничего за инференс.
Где Flash реально окупается. Массовая генерация однотипного кода (CRUD-эндпоинты, типовые компоненты, заглушки тестов). Парсинг и приведение данных в форматы. Скрипты автоматизации, где не нужна архитектурная глубина. В таких задачах разница между 80% и 88.6% SWE-bench не заметна, а разница в счете — в 35 раз.
Связка из практики. План пишется в GPT-5.5 (10 000 токенов). Архитектурный код — в Opus 4.8 (50 000 токенов). А вот 200 однотипных компонентов или массовый ре-форматинг кодовой базы спокойно делегируется DeepSeek V4 Flash. Счет в конце дня — раза в три-четыре ниже.

Где Flash сдается. Сложный рефакторинг с переходом между файлами и неочевидной зависимостью между модулями. Тут он начинает галлюцинировать имена функций.
Как собрать рабочую связку из нескольких моделей под полный цикл?
Стандартная связка для вайбкодинга в 2026 году: GPT-5.5 для плана, Claude Opus 4.8 для кода, Gemini 3.1 Pro или Qwen3.7 Max для полировки UI, DeepSeek V4 Flash для всего массового. Под мониторинг — Reflection Loop.
Reflection Loop — паттерн саморедактирования, при котором модель пишет код, затем сама же запускает тесты или линтер, читает вывод и исправляет ошибки. По свежим разборам разработчиков, на стрессовых задачах с PHP Lint и Grafana K6 этот паттерн дает в 2-3 раза более стабильный результат, чем одиночный промпт.
Как это выглядит на практике. Утром садитесь и ставите задачу в GPT-5.5: «спроектируй фичу X с учетом архитектуры Y». Получаете план на 1-2 страницы. Берете этот план, отдаете в Opus 4.8 в Cursor или Claude Code, и он пишет рабочий код. Когда логика встала — переключаетесь на Gemini 3.1 Pro для финальной полировки интерфейса. Юнит-тесты и заглушки делегируете DeepSeek V4 Flash.
И отдельно про git. Перед каждым переключением модели — коммит. Особенно перед Gemini. Если что-то уходит в петлю, откатываетесь и не теряете час работы. Это не паранойя, это просто опыт.
Если вам нужно, чтобы все это делал один автономный агент — это уже про MCP-сервера, кастомные пайплайны и оркестрацию. Подробности есть в нашем каталоге AI-агентов.

Максим: «Портал VibeCoderz мы собрали за неделю тремя скриптами голосом в Claude Code. 6 200 материалов, в первый месяц 4 303 посетителя и 36 000 показов в Google. Под каждый скрипт брал свою модель. Где надо думать архитектурно — шел в Opus. Где гнать однотипный код — переключался на дешевую. Будь у меня одна модель на все, собирали бы месяц.»
Сколько стоят лучшие ИИ для программирования в 2026 году
Цены различаются в 70 раз — от $0.14 до $10 за миллион входных токенов. Премиум-тир и бюджет-тир по качеству разъехались на 15-20 процентных пунктов, но не на порядок.
Тир S+ (Claude Fable 5, $10/$50) дает 95.0% SWE-bench. Тир B (DeepSeek V4 Pro Max, $0.435/$0.87) — 80.6%. Разница в SWE-bench — 14.4 п.п., разница в цене — в 23 раза. На большинстве реальных задач (не на бенчмарках) разрыв в качестве заметен только на сложном рефакторинге и архитектуре.
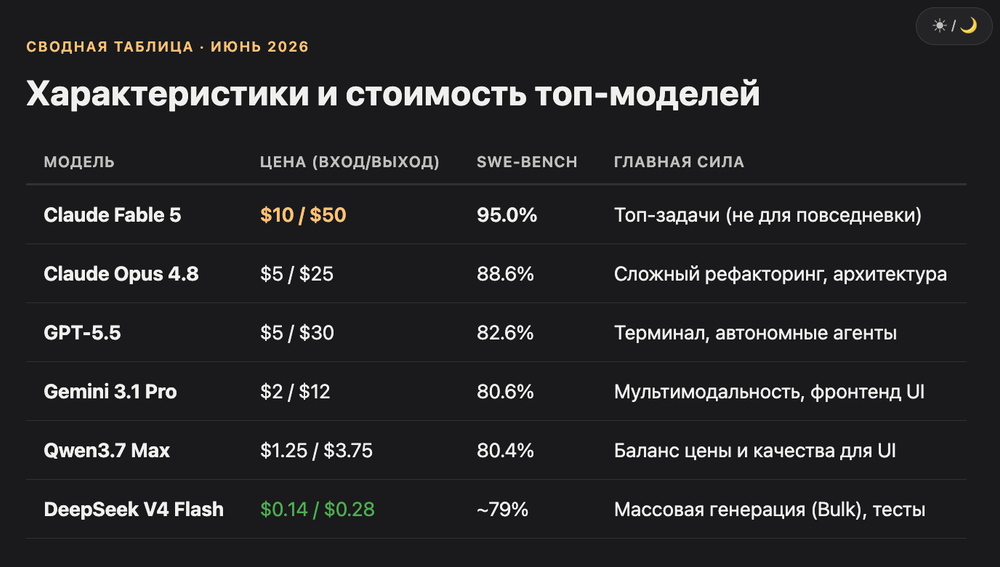
Таблица ниже сравнивает топ моделей на июнь 2026 года. Цены указаны за миллион токенов, формат «вход/выход».
| Модель | Цена | SWE-bench Verified | Контекст | Сильна в |
|---|---|---|---|---|
| Claude Fable 5 | $10/$50 | 95.0% | 1M | Топ-задачи, не для повседневки |
| Claude Opus 4.8 | $5/$25 | 88.6% | 1M | Рефакторинг, архитектура |
| GPT-5.5 | $5/$30 | 82.6% | 1.05M | Терминал, агенты, планы |
| Gemini 3.1 Pro | $2/$12 | 80.6% | 1M | Большие кодбазы, мультимодальность |
| Claude Sonnet 4.6 | $3/$15 | 79.6% | 1M | Универсальный старт |
| Qwen3.7 Max | $1.25/$3.75 | 80.4% | 1M | Фронтенд, баланс цены |
| Kimi K2.6 | $0.75/$3.50 | 80.2% | 128K | Long-horizon агенты |
| DeepSeek V4 Pro Max | $0.435/$0.87 | 80.6% | 1M | Self-host, MIT |
| DeepSeek V4 Flash | $0.14/$0.28 | ~79% | 1M | Bulk, эксперименты |
| Claude Haiku 4.5 | $1/$5 | n/a | 200K | Лидер по cost-per-point ($0.13) |
Источник цен и бенчмарков: OpenRouter Models, SWE-bench Verified Leaderboard, CloudPrice, MorphLLM на июнь 2026 года.
Что важно учесть. Цены OpenRouter — не единственный источник. У DeepSeek на официальном API постоянная скидка 75%. У Anthropic в Pro/Max-подписке до 22 июня Fable 5 был бесплатно. У NVIDIA Nemotron 3 Super и Ultra есть полностью бесплатные тиры.
Кому какая модель подходит для разных задач
Карта выбора по сегментам: джуниор берет Sonnet 4.6 или DeepSeek V4 Pro, миддл — связку Opus + GPT, сеньор и архитектор — Opus 4.8 + Fable 5 на критичные участки. Студент и пет-проект — бесплатный Nemotron или DeepSeek V4 Flash.
Базовое правило 2026 года для команд от 3 человек: одна основная модель (Sonnet 4.6 или Opus 4.8) плюс одна дешевая (DeepSeek V4 Flash или Qwen3.7 Plus) для bulk. Бюджет на токены при таком сетапе у команды из 5 разработчиков — $300-800 в месяц вместо $2000+ на чистом Opus.
Под конкретные ситуации:
- Джуниор, учусь, пет-проект. Claude Sonnet 4.6 ($3/$15) или DeepSeek V4 Pro в Cursor. Хватит для 95% учебных задач. Бесплатные Nemotron 3 Super через OpenRouter — для совсем нулевого бюджета.
- Миддл в продуктовой команде. Связка Opus 4.8 + GPT-5.5 + DeepSeek V4 Flash для массового. Раздельные тарифы под задачи, общий счет ниже.
- Сеньор, лид, архитектор. Opus 4.8 в Claude Code как основной. Fable 5 ($10/$50) включается под критичный рефакторинг и архитектурные решения. GPT-5.5 — для агентских пайплайнов и DevOps.
- Вайбкодер, делает свои продукты. Opus 4.8 на ядро + Gemini 3.1 Pro или Qwen3.7 Max на UI + DeepSeek V4 Flash на типовой код. Если хочется автономности — Kimi K2.6 для long-horizon агентов.
- Команда на 5-10 человек, бюджет важен. DeepSeek V4 Pro Max в self-host. 80.6% SWE-bench при нулевой стоимости инференса после установки. Opus подключается как fallback.
Если вам нужен бесплатный старт без подписок — смотрите каталог AI IDE на VibeCoderz, там собраны инструменты с бесплатными тарифами и моделями по умолчанию.
FAQ по выбору ИИ для программирования
Какая нейросеть лучше для программирования прямо сейчас, в июне 2026? На вершине — Claude Fable 5 с 95% SWE-bench, но за $10/$50 это не для повседневки. Рабочий выбор большинства — Claude Opus 4.8 ($5/$25, 88.6%) или связка Opus + GPT-5.5 + Qwen3.7 Max под разные задачи. Универсального ответа нет.
Что лучше для джуна — Cursor или Claude Code? Cursor проще для старта (IDE с подсказками, привычный VS Code-интерфейс), Claude Code сильнее в агентских задачах и автоматизации в терминале. Если только начинаете — Cursor с моделью Sonnet 4.6. Если работа уже в терминале и с длинными задачами — Claude Code.
Можно ли обойтись только бесплатными ИИ для кода? Можно. Nemotron 3 Super и Ultra от NVIDIA имеют полностью бесплатные тиры на OpenRouter. DeepSeek V4 Flash стоит $0.14 за миллион входных токенов — это копейки даже для 100 запросов в день. Кроме того, Qwen3 Coder 480B с open-weights разворачивается на своем железе.
Какой ИИ лучше для написания тестов? GPT-5.5 в режиме codex или GPT-5.3 Codex ($1.75/$14). Эти модели обучены на большом объеме тестового кода и реже галлюцинируют моки. На bulk-генерации заглушек подключайте DeepSeek V4 Flash для удешевления.
Стоит ли переходить с Claude на китайские модели в 2026? DeepSeek V4 Pro Max и Qwen3.7 Max догнали Gemini 3.1 Pro по SWE-bench (в пределах 0.2 п.п.). В России это особенно актуально — оплата напрямую часто проще через российских агрегаторов. Для архитектурных задач Claude пока сильнее, для повседневного кодинга разница на реальных проектах минимальна.
Сколько в среднем стоит месяц активной разработки с ИИ? Для одного разработчика на Opus 4.8 в Cursor — около $40-150 в месяц при активном использовании. На связке Opus + DeepSeek V4 Flash — $25-80. На чистом DeepSeek — $5-15. Точная цифра зависит от длины контекста и количества правок.
Что выбрать для фронтенда — Gemini или Qwen? Gemini 3.1 Pro дает более предсказуемый и красивый UI, но в 2 раза дороже Qwen3.7 Max ($2/$12 против $1.25/$3.75). Если бюджет важен — Qwen. Если UI критичен и нужен запас по контексту для большого проекта — Gemini.
Глоссарий терминов из статьи
SWE-bench Verified — стандартизированный бенчмарк по решению реальных задач из GitHub-репозиториев. Чем выше процент — тем больше задач модель решает с первого раза без правок человеком.
Terminal-Bench — бенчмарк по задачам в терминале: модель сама запускает команды, читает вывод, корректирует подход. Важен для агентских сценариев.
Reflection Loop — паттерн саморедактирования. Модель пишет код, сама запускает тесты или линтер, читает результат и исправляет ошибки в следующей итерации.
MoE (Mixture of Experts) — архитектура, в которой активируется только часть параметров на каждый запрос. У DeepSeek V4 Flash из 284B параметров активны 13B. Это снижает стоимость инференса в разы.
Контекст (context window) — сколько токенов модель помнит за один диалог. 1M токенов — это примерно 750 000 слов или вся кодовая база среднего проекта.
Vendor harness vs Scale SEAL — разные способы запуска SWE-bench. Vendor harness — настройка от разработчика модели (обычно выше оценки). Scale SEAL — независимая стандартизированная среда (обычно ниже).
Citation capsule — выделенный самодостаточный блок текста, который AI-системы (ChatGPT, Perplexity) берут как готовую цитату для ответа пользователю.
Что делать дальше. Если выбираете под себя — посмотрите развернутые карточки моделей и IDE в каталоге AI-инструментов VibeCoderz. Если нужен индивидуальный разбор стека под ваш проект и команду — запишитесь на консультацию к Максиму. За час разберем, какие модели сэкономят вам деньги и время, а от каких подписок стоит отказаться прямо сейчас.
Статья обновлена в июне 2026 года. Цены и бенчмарки актуальны на дату публикации.