Китайские модели DeepSeek, Qwen и Kimi в 2026 уже достигают уровня Claude Sonnet в кодировании, при этом стоимость 5–30 раз ниже флагманов Anthropic, что меняет экономику AI-разработки.
400 000+ органических переходов за 3 месяца. Со-основатель GoBanana (231K пользователей, 12+ млн ₽ без рекламы) и NeuroScribe (65K пользователей). SEO/GEO-стратегии для AI-поисковиков, 1 700+ единиц контента, 17+ реализованных стратегий.
Об авторе →Claude Code: новый CLI-агент от Anthropic
Anthropic выпустила Claude Code — терминальный AI-агент для разработчиков. Инструмент работает прямо в командной строке и умеет писать, редактировать и запускать код.
Zcode AI: Полный гид по визуальному интерфейсу для Claude Code и AI-агентов
Узнайте, как использовать Zcode для управления Claude Code, Gemini и Codex в едином GUI. Настройка провайдеров, MCP-серверов и визуальный вайбкодинг.
YouTube-канал с монетизацией из любой точки мира: Пошаговый гайд 2026
Инструкция по созданию YouTube-канала: обход блокировок SMS, настройка расширенных функций через виртуальные номера и правила безопасности для монетизации.
Windsurf Code Maps: Как глубоко понимать архитектуру проекта перед написанием кода
Полный гайд по Windsurf Code Maps, модели Sway 1.5 и Sway Grep. Узнайте, как визуализировать архитектуру кода и ускорить разработку в 13 раз.
Vk Fast Cash Strategy
Аудитория ВКонтакте — это те же люди, что и в Instagram, но 'социальный контракт' площадки другой. Если Instagram — это 'дорогой ресторан' с демонстрацией успеха, то VK — это 'душевная шашлычная'. Здесь не работает глянцевый 'успешный успех

Год назад китайские нейросети для программирования занимали меньше 2% токенов на OpenRouter. Сегодня их доля выросла до 45%+, а четыре модели держат планку SWE-bench Verified в районе 80% и стоят в 5–30 раз дешевле флагманов Anthropic. Разберем, кто из них реально пригоден для ежедневной работы, а кто красиво смотрится только в бенчмарках. По дороге сравним с Claude Opus 4.8 и GPT-5.5.
TL;DR. В июне 2026 четыре китайские модели держат уровень Claude Sonnet 4.6 на коде. DeepSeek V4 Pro Max (80.6%, MIT, $0.435/$0.87), Qwen3.7 Max (80.4%, $1.25/$3.75), MiniMax M3 (80.5%, $0.30/$1.20) и Kimi K2.6 (80.2%, $0.75/$3.50, #1 по объему на OpenRouter). Они закрывают 80–90% задач за 5–30% бюджета. Топ-Anthropic все еще впереди по сложным архитектурным сценариям.
Обновлено: июнь 2026.
Дело в open-weights, MoE-архитектуре и агрессивной цене. К июню 2026 разрыв между Gemini 3.1 Pro и тройкой DeepSeek, MiniMax, Qwen на SWE-bench Verified составляет 0.2 процентных пункта.
Год назад флагман Anthropic стоил в 200 раз дороже лучшей китайской модели и опережал ее на 15 пунктов в кодинге. К июню 2026 разрыв на SWE-bench Verified сжался до 8 пунктов (88.6% против 80.6%), а ценовой до 10–15 раз. Это меняет экономику AI-разработки целиком. 10 миллионов токенов в день на Claude Opus 4.8 обходятся примерно в $58 000 в год, на DeepSeek V4 Pro Max около $4 000.

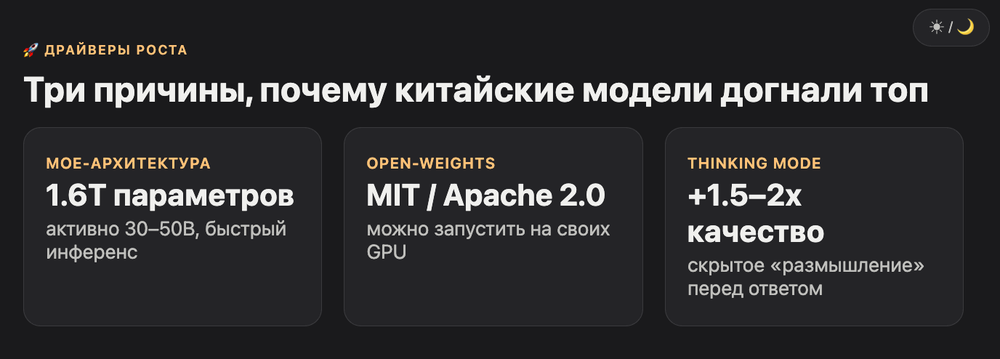
Драйверов три. Первый, MoE-архитектура (mixture of experts), где из триллиона параметров активны 30–50 миллиардов. Второй, открытые веса с лицензией MIT, можно поставить на свои GPU. Третий, режим thinking, который ChatGPT, Claude и китайцы освоили примерно одновременно.
Год назад был один frontier-провайдер с моделью уровня 80% SWE-bench. Сейчас их семь, и четыре из Китая. Внутри России это означает практический сдвиг. Оплата зарубежных API упростилась через OpenRouter и отечественные шлюзы, а открытые веса DeepSeek и MiniMax можно крутить локально без внешних платежей вообще.
DeepSeek V4 Pro Max это лучший open-weight кодер с показателем 80.6% на SWE-bench Verified. Цена $0.435/$0.87 за миллион токенов, лицензия MIT, контекст 1M. Подходит для high-volume задач и self-host.

DeepSeek V4 Pro Max использует архитектуру MoE на 1.6 триллиона общих параметров и 49 миллиардов активных. SWE-bench Verified показывает 80.6%, равенство с Gemini 3.1 Pro. Цена в 10–12 раз ниже Claude Opus 4.8 при сопоставимом результате. MIT-лицензия снимает все вопросы с self-host и приватностью данных.
На реальных тестах с поиском багов модель часто находит то, что пропускают другие. В сравнении с Claude Opus 4.7 и GPT-5.5 на одном из YouTube-тестов V4 Pro выдал 13 багов против 5 у Claude и 4 у GPT, включая критическую дыру в Stripe-вебхуке.
Но есть и обратная сторона. На задачах с UI и фронтендом модель отстает. Лендинг, который сгенерил V4 Pro в одном из публичных сравнений, оказался ближе всех к копированию существующего варианта от Codex. Качество дизайна хуже, чем у Claude и Qwen3.7. На live-кодинге реалтаймовых приложений V4 Pro проваливает Flask-приложения с WebSocket в первом подходе чаще, чем Kimi и MiMo.
Кому подойдет. Бэкенд-разработчику с высоким объемом запросов (десятки миллионов токенов в день). Команде, которой важна приватность кода и self-host. Бюджетным агентским пайплайнам, где Claude становится финансово неподъемным. Подробный обзор есть в каталоге AI IDE.
Qwen3.7 Max это китайский флагман с 80.4% SWE-bench Verified и AA Index 56.6. Цена $1.25/$3.75, в шесть раз дешевле Claude Opus 4.8. Лидер по агентскому кодингу и frontend-задачам.
Qwen3.7 Max вышел в июне 2026 с заявкой на «рациональную альтернативу Opus 4.8 за одну шестую цены». SWE-bench Pro (vendor harness) составляет 60.6%, что выше любого open-source конкурента. Контекст 1M токенов, отдельный режим для agentic-сценариев с тысячами вызовов инструментов.
На сложных мультиязычных и культурно-чувствительных задачах Qwen стабильно входит в тройку лучших, иногда обгоняя Claude по точности нюансов. На фронтенде Qwen3.7 умеет в чистый адаптивный дизайн с правильной типографикой и spacing, в чем DeepSeek проседает.
Слабое место касается стабильности при долгих агентских сессиях. В тестах open-кода Qwen3.7 успешно собирает 3D-сцену с орбитами планет и тенями, но иногда залипает на повторных билдах через openrouter. Не критично, но требует внимательного провайдер-роутинга.
Для российских разработчиков ключевой плюс это отсутствие проблем с оплатой и стабильный доступ через OpenRouter. Можно использовать как ежедневный driver вместо Cursor с подпиской на Claude.
MiniMax M3 (31 мая 2026) показывает 80.5% на SWE-bench Verified, что на уровне Gemini 3.1 Pro. Цена $0.30/$1.20 за миллион токенов, в 17 раз дешевле Claude. Контекст 1M, мультимодальность, open-weights.

MiniMax M3 это главный сюрприз июня 2026. По SWE-bench Verified модель отстает от Claude Opus 4.8 на 8 пунктов, но цена ниже в 17 раз. $0.30 за миллион входных токенов против $5 у Anthropic. Архитектура поддерживает 1M контекста и мультимодальность, а веса обещают открыть.
Но на практических тестах кодинга реалтаймовых приложений MiniMax регулярно проваливается. В одном из публичных тестов модель не смогла собрать рабочее Flask-приложение с CRUD-операциями для code review. Приложение запускалось, но любая операция возвращала пустоту. То же повторилось в тесте с играми, экран после загрузки оставался пустым.
Что это значит для разработчика. MiniMax M3 это отличный выбор для batch-задач, генерации структурированных данных, текстовых обработок и аналитики. Для production-grade приложений с многокомпонентной архитектурой пока ненадежен. Простой эвристикой. Если задача укладывается в один шот без сложного state management, MiniMax справится за копейки. Если нужно держать состояние и интегрировать пять систем, берите Qwen или Kimi.
Kimi K2.6 от Moonshot AI лидер по weekly tokens на OpenRouter (1.36T). SWE-bench Verified 80.2%, цена $0.75/$3.50. Специализация на long-horizon агентах и batch-нагрузках.
Kimi K2.6 это самая используемая модель на OpenRouter в июне 2026, обгоняющая даже Claude Sonnet 4.6 и Gemini 3 Flash по объему токенов. Архитектура MoE с 1T общих и 32B активных параметров. До 300 параллельных субагентов в одной сессии. Контекст ограничен 128K, что мало для длинных кодовых баз.

Сильная сторона Kimi заключается в стабильности на длинных задачах. Где Claude Opus 4.8 начинает «дрейфовать» от первоначального запроса после 50–60 итераций, Kimi держит линию. Это критично для агентских пайплайнов, ночных билдов и автоматизации тестов.
На прямом сравнении с пятью китайскими моделями в реалтаймовых Flask-приложениях Kimi показал лучший real-time опыт с первого захода. Сессии работали, коллаборация шла, комментарии сохранялись. Из шести моделей только Kimi и MiMo собрали полностью рабочий продукт без правок.
Минус касается небольшого контекста 128K. Для больших монорепо лучше брать Qwen или DeepSeek с их 1M. Для типовых сценариев (рефактор файла, написание модуля, генерация серии скриптов) Kimi оптимален. В нашем каталоге для агентов есть подборка под задачу.
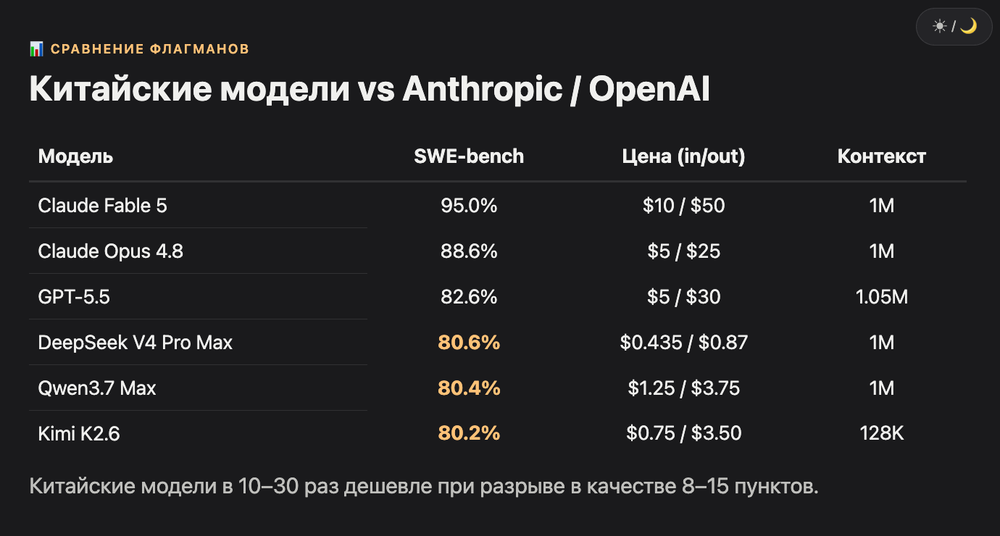
По SWE-bench Verified Claude Fable 5 (95%) и Opus 4.8 (88.6%) сохраняют отрыв в 8–15 пунктов. По цене китайские модели в 10–30 раз дешевле. Для большинства задач разница в качестве несущественна, для архитектурных критична.
Разрыв на SWE-bench Verified между Claude Fable 5 и тройкой китайских лидеров составляет 14.4–14.6 пунктов. Между Opus 4.8 и китайцами около 8 пунктов. Но на задачах ниже сложности «сборка системы с нуля» разница часто незаметна. По цене Opus 4.8 стоит $5/$25 за 1M токенов, DeepSeek V4 Pro Max $0.435/$0.87. В 12 раз меньше.
Сводная таблица по топ-моделям июня 2026:
| Модель | SWE-bench Verified | Цена input/output (за 1M) | Контекст | Лучше всего для |
|---|---|---|---|---|
| Claude Fable 5 | 95.0% | $10 / $50 | 1M | Архитектура, сложный анализ |
| Claude Opus 4.8 | 88.6% | $5 / $25 | 1M | Frontend, рефакторинг больших систем |
| GPT-5.5 | 82.6% | $5 / $30 | 1.05M | Terminal-задачи, тесты |
| Claude Sonnet 4.6 | 79.6% | $3 / $15 | 1M | Универсальный ежедневный кодинг |
| Gemini 3.1 Pro | 80.6% | $2 / $12 | 1M | Большие кодовые базы |
| Qwen3.7 Max | 80.4% | $1.25 / $3.75 | 1M | Frontend, agentic-задачи |
| Kimi K2.6 | 80.2% | $0.75 / $3.50 | 128K | Long-horizon агенты |
| DeepSeek V4 Pro Max | 80.6% | $0.435 / $0.87 | 1M | Bug-hunting, self-host |
| MiniMax M3 | 80.5% | $0.30 / $1.20 | 1M | Batch-обработка, генерация |

Простое правило выбора. Архитектура и критичный код -> Claude Opus 4.8 или Fable 5. Ежедневный кодинг -> Sonnet 4.6 или Qwen3.7 Max. Большой объем -> DeepSeek V4 Pro Max или MiniMax M3. Агенты с длинной памятью задач -> Kimi K2.6. Сводка по моделям обновляется ежемесячно в каталоге AI IDE.
У китайских моделей три ключевых ограничения. Open-weights не равно open-source (данные обучения закрыты). Маршрутизация трафика через китайские серверы при использовании официальных API. Нестабильность качества при agentic-сессиях.

Главный риск заключается в том, что открытые веса не означают открытый код или открытые данные обучения. Это значит, можно запустить модель локально, но нельзя проверить, что в нее зашили. На политически чувствительных запросах китайские модели уходят в самоцензуру и фактуальное искажение. Для кода это менее критично, для копирайтинга и аналитики важно.
Второй риск касается приватности кода. При использовании официальных API DeepSeek, MiniMax, Qwen ваш код уходит на серверы в КНР. Юрисдикция другая. Регуляторика другая. Для корпоративного использования в финансах, healthcare и юриспруденции это часто блокер.
Третий момент это провайдер-роутинг через OpenRouter. У одной и той же модели бывает три-четыре провайдера, и качество отличается. На сравнениях иногда видно. Один провайдер DeepSeek дает 80% бенчмарка, другой проваливается до 70%. Решение в настройках OpenRouter включать routing по latency или конкретному провайдеру (Fireworks, Together, DeepInfra обычно стабильнее).
Честная оговорка. Бенчмарки модели сами публикуют, и cherry-picking частая история. Например, в анонсе DeepSeek V4 модель сравнивалась с Claude 4.6 и GPT-5.4, а не с актуальными 4.8 и 5.5. Реальные тесты пользователей на сложных задачах часто показывают другую картину, чем графики из релизов.
Максим: «У нас в VibeCoderz 6 200 материалов, портал собрали за неделю тремя скриптами голосом в Claude Code. Когда лопатишь такие объемы, цена за миллион токенов перестает быть абстракцией. Сделал, получил цифру. На DeepSeek V4 такой же пайплайн обходится в 10–12 раз дешевле, чем на Opus. Для разовой архитектурной задачи беру Opus. Для конвейера китайцев.»

Кратко. Для архитектуры и сложных рефакторингов Claude Opus 4.8. Для ежедневного frontend и agentic-задач Qwen3.7 Max. Для bulk-задач и self-host DeepSeek V4 Pro Max. Для длинных агентских сессий Kimi K2.6.
Выбор модели это всегда tradeoff между качеством, ценой и инфраструктурой. В 2026 году нет одной «лучшей нейросети для программирования», есть оптимум под сценарий. Архитектурная задача на пару часов оправдывает $50 на Opus. Конвейер на миллионы токенов нет.
Финальная карта выбора по типу работы:
| Сценарий | Рекомендация | Почему |
|---|---|---|
| Старт проекта, архитектура | Claude Opus 4.8 | Лучший на сложном анализе |
| Ежедневный кодинг | Claude Sonnet 4.6 / Qwen3.7 Max | Баланс цена/качество |
| Frontend и UI | Claude Opus 4.8 / Qwen3.7 Max | Лучшие в дизайне и адаптивке |
| Bug hunting | DeepSeek V4 Pro Max | Находит больше за счет thinking |
| Большие кодовые базы (>500K токенов) | Gemini 3.1 Pro / DeepSeek V4 | Контекст 1M, дешево |
| Агентские пайплайны | Kimi K2.6 | Стабильность на длинных задачах |
| Batch-генерация | MiniMax M3 / DeepSeek V4 Flash | Минимальная цена |
| Self-host | DeepSeek V4 Pro Max / Qwen3 Coder 480B | MIT и open-weights |
Связка дня для российской команды разработки. Cursor с подключенным OpenRouter, основная модель Qwen3.7 Max ($1.25/$3.75, приемлемо для ежедневной работы), при сложных архитектурных моментах переключение на Claude Code через MAX-план. Для night builds и автотестов Kimi K2.6 в фоне.
Доверие к коду да, при базовых мерах. Проверка ключевой логики, изоляция от прода до тестов, использование надежных провайдеров через OpenRouter. Доверие к фактам и аналитике с оговорками, есть смещения в политически чувствительных темах.
Для кодовой генерации китайские модели в 2026 году рабочий инструмент. Бэкенд-логика, фронтенд, тесты, рефакторинг, ревью закрываются на 80–90% так же, как Claude и GPT, за 5–20% бюджета. Для критичных систем (платежи, безопасность, медицина) нужна обязательная ручная проверка плюс параллельная генерация на Opus.
Практический подход. Использовать китайские модели для черновика и объема. Использовать Anthropic для финальной шлифовки и архитектурных решений. Никогда не отправлять чувствительный код на официальные API китайских провайдеров. Только через OpenRouter с прокси, либо self-host для DeepSeek с MIT-лицензией.
Если задача похожа на конвейер контента или однотипных скриптов, берите DeepSeek V4 Pro Max или MiniMax M3. Если работаете с уникальной архитектурой в проде, Claude Opus 4.8 окупится. Подробные обзоры всех IDE и сравнения моделей собраны в каталоге AI IDE.
По SWE-bench Verified лучшие DeepSeek V4 Pro Max и MiniMax M3 (80.5–80.6%). По агентским задачам Qwen3.7 Max и Kimi K2.6. Универсального лидера нет, выбор зависит от сценария. Для большинства задач разработчика подойдет Qwen3.7 Max.
Для 80–90% типовых задач да. Frontend, рефакторинг файлов, написание модулей, тесты, документация. Qwen3.7 Max и Kimi K2.6 справляются на сопоставимом уровне. Для сложной архитектуры и системных решений Claude Opus 4.8 остается точнее.
Через официальный API нет, данные уходят на серверы КНР. Через OpenRouter с надежным провайдером (Fireworks, Together) приемлемо для большинства задач. Для self-host (модель открыта по MIT) полностью под вашим контролем.
DeepSeek V4 Pro Max сильнее в bug-hunting и backend-логике, имеет 1.6T параметров и MIT-лицензию. MiniMax M3 дешевле на 30%, проще для batch-задач, но ненадежен на сложных интерактивных приложениях. Для разработчика DeepSeek универсальнее.
Для первых шагов в вайбкодинге достаточно бесплатных тиров. Nemotron 3 Super на OpenRouter работает бесплатно. Qwen3.7 Plus стоит $0.40/$1.60 за 1M токенов, баланс цены и качества для обучения. Подробный гайд для новичков есть на портале VibeCoderz.
Qwen3.7 Max и Claude Opus 4.8. Qwen уверенно делает адаптивный дизайн, грамотную типографику, чистый CSS. Opus сильнее в сложных интерактивных компонентах и анимациях. DeepSeek в этом сегменте отстает.
Через OpenRouter (openrouter.ai) самый стабильный вариант с оплатой картой или криптой. Через российские шлюзы для OpenRouter API. Для DeepSeek и Qwen работает self-host на собственных GPU, веса доступны на Hugging Face по MIT и Apache 2.0.
SWE-bench Verified. Стандартный бенчмарк для оценки нейросетей на реальных задачах GitHub-разработки. Чем выше процент, тем больше Pull Request моделей действительно решают задачу.
MoE (Mixture of Experts). Архитектура, где из всех параметров модели активны не все, а только небольшая часть (эксперты), нужная для конкретного запроса. Позволяет иметь триллион параметров и быстрый инференс одновременно.
Open-weights. Открытые веса модели. Можно скачать и запустить локально. Не означает открытого кода обучения и открытых данных.
MIT-лицензия. Самая свободная лицензия для open-source. Разрешает коммерческое использование без ограничений.
Контекст (context window). Максимальное количество токенов, которое модель удерживает в одной сессии. 1M контекста это около 750 000 слов или 4 000 страниц кода.
OpenRouter. Агрегатор API доступа к десяткам моделей через единый интерфейс. Удобно для российских разработчиков. Одна оплата покрывает Claude, GPT, DeepSeek, Qwen, Kimi сразу.
Thinking mode. Режим, в котором модель сначала «думает» в скрытом контексте, а потом выдает ответ. Повышает качество на сложных задачах в 1.5–2 раза, увеличивает стоимость и latency.
Self-host. Запуск модели на собственной инфраструктуре. Требует GPU класса H100 для крупных моделей. Полностью снимает вопросы приватности кода.
Подведем итог. В июне 2026 китайские нейросети для программирования это рабочий инструмент с понятной экономикой. DeepSeek V4 Pro Max и MiniMax M3 закрывают bulk-задачи в 10–17 раз дешевле Claude. Qwen3.7 Max и Kimi K2.6 это оптимум для ежедневного кодинга. Anthropic и OpenAI остаются лидерами по архитектурным задачам, но монополии больше нет.
Полный обзор инструментов для вайбкодинга собран в каталоге AI IDE на vibecoderz.ru/ide. Если хочется разобрать ваш сетап и подобрать связку моделей под конкретный продукт, запишитесь на консультацию к Максиму.
Источники. OpenRouter Rankings, SWE-bench Verified Leaderboard, MorphLLM Best AI Model for Coding June 2026.
Статья обновлена: июнь 2026.