20 мая 2026 года на Alibaba Cloud Summit в Ханчжоу вышел Qwen3.7-Max — новый reasoning-флагман от Alibaba Qwen Team. До официального анонса модель тихо тестировалась на Arena AI с 14 мая: пользователи замечали что-то мощное в анонимных баттлах, но не…
10+ лет в маркетинге, 300+ клиентских проектов: сайты, реклама, боты. Создатель GoBanana (228K+ пользователей, 11.6 млн ₽ выручки) и VibeCoderz. Делаю AI-продукты сам через Claude Code, Cursor, Windsurf и консультирую тех, кто хочет так же.
Об авторе →Claude Code: новый CLI-агент от Anthropic
Anthropic выпустила Claude Code — терминальный AI-агент для разработчиков. Инструмент работает прямо в командной строке и умеет писать, редактировать и запускать код.
Zcode AI: Полный гид по визуальному интерфейсу для Claude Code и AI-агентов
Узнайте, как использовать Zcode для управления Claude Code, Gemini и Codex в едином GUI. Настройка провайдеров, MCP-серверов и визуальный вайбкодинг.
YouTube-канал с монетизацией из любой точки мира: Пошаговый гайд 2026
Инструкция по созданию YouTube-канала: обход блокировок SMS, настройка расширенных функций через виртуальные номера и правила безопасности для монетизации.
Windsurf Code Maps: Как глубоко понимать архитектуру проекта перед написанием кода
Полный гайд по Windsurf Code Maps, модели Sway 1.5 и Sway Grep. Узнайте, как визуализировать архитектуру кода и ускорить разработку в 13 раз.
Vk Fast Cash Strategy
Аудитория ВКонтакте — это те же люди, что и в Instagram, но 'социальный контракт' площадки другой. Если Instagram — это 'дорогой ресторан' с демонстрацией успеха, то VK — это 'душевная шашлычная'. Здесь не работает глянцевый 'успешный успех
20 мая 2026 года на Alibaba Cloud Summit в Ханчжоу вышел Qwen3.7-Max — новый reasoning-флагман от Alibaba Qwen Team. До официального анонса модель тихо тестировалась на Arena AI с 14 мая: пользователи замечали что-то мощное в анонимных баттлах, но не понимали что. Теперь понятно.
Главный тезис Alibaba: это не «ещё один Claude-киллер». Qwen3.7-Max — агентная модель, заточенная под длинные автономные воркфлоу. Один непрерывный прогон на реальной задаче — 35 часов, 1158 вызовов инструментов, без деградации. Разбираем что внутри, где обгоняет конкурентов и где честно проигрывает.

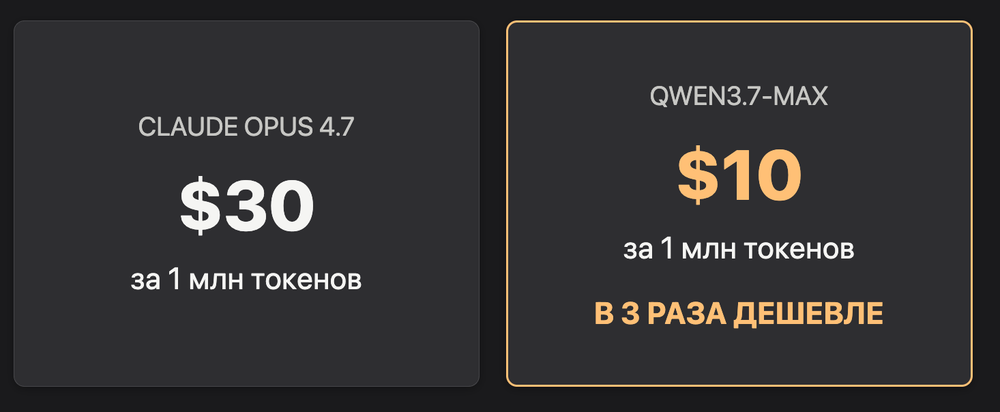
Qwen3.7-Max — текстовая reasoning-модель с 1M контекстом, $10 за миллион токенов (против $30 у Claude Opus 4.7). Бенчмарки по кодингу на уровне Claude Opus 4.6, на некоторых agent-задачах — лучше. Подключается к Claude Code через три строки в терминале. Слабость — knowledge recall: модель предпочитает сказать «не знаю», чем ошибиться. Бесплатный чат на chat.qwen.ai, API через Alibaba Cloud Model Studio.

Прежде чем смотреть на бенчмарки — важно понять что реально изменилось:
Контекстное окно выросло с 256K до 1 миллиона токенов — это примерно 1500 страниц A4. Максимальный вывод — 64K токенов. Это делает модель полноценным инструментом для работы с большими кодовыми базами без обрезания контекста.
Agent-First архитектура вместо частичной: модель тренировалась на 8200+ разных агентных окружений, и каждые дополнительные среды линейно улучшали средний ранг на 8 agent-бенчмарках — с #9 у базовой версии до #3 у финальной. Это не маркетинговая цифра, а задокументированная кривая обучения.
Cross-harness generalization — новая фича: модель работает одинаково через Claude Code, OpenClaw, Qwen Code и любой OpenAI-compatible клиент без потери производительности. Не нужно выбирать «свою» среду.
Artificial Analysis Intelligence Index вырос с 51.8 до 56.6 (+4.8 пункта) — пятое место в мировом рейтинге.

Здесь Qwen3.7-Max выглядит сильнее всего. GPQA Diamond — 92.4 против 91.3 у Claude Opus 4.6. Humanity's Last Exam — 41.4 против 40.
Самый заметный разрыв на Apex Math: 44.5 у Qwen против 34.5 у Claude Opus 4.6 и 38.3 у DeepSeek V4 Pro. Это не маленькая дельта — разрыв в 10 пунктов на одном из сложнейших математических бенчмарков.
| Бенчмарк | Qwen3.7-Max | Claude Opus 4.6 | Лучший |
|---|---|---|---|
| SWE-bench Verified | 80.4 | 80.8 | Opus 4.6 |
| SWE-bench Pro | 60.6 | 57.3 | Qwen |
| SWE-Multilingual | 78.3 | — | Qwen |
| Terminal Bench 2.0 | 69.7 | 69.4 (Opus 4.7) | Паритет |
| MCP-Atlas | 76.4 | 75.8 | Qwen |
| MCP-Mark | 60.8 | — | Qwen |
| SpreadSheetBench-v1 | 87 | — | Qwen |
Честный нюанс: Alibaba сравнивает с Claude Opus 4.6, а не 4.7. На Terminal Bench 2.0 новый Opus 4.7 показывает 69.4% — уже практически ничья. GPT-5.5 на том же бенчмарке набирает 82.7% — и его в таблицах Alibaba нет. Это важно держать в голове.
На BenchLM.ai в head-to-head против Claude Opus 4.6 агрегатный счёт 93 vs 87 в пользу Qwen — за счёт кодинга (+9.2). По knowledge и agentic категориям Opus 4.6 впереди.
На AA-Omniscience (тест фактической точности) у Qwen3.7-Max attempt rate 48% — самый низкий среди всех frontier-моделей. Модель предпочитает сказать «не знаю» вместо того чтобы ошибиться. Raw accuracy при этом выросла, hallucination rate упал с 44.2% до 22.9%. Но если вам нужна модель которая уверенно отвечает на фактические вопросы — это ограничение.

Это самый обсуждаемый эпизод вокруг Qwen3.7-Max — и стоит разобраться что именно там было.
Условия: T-Head ZW-M890 PPU — чип, который модель никогда не видела при обучении. На входе: только описание задачи, reference-скрипт и evaluation. Никакой документации, никаких profiling-данных, никаких примеров кода под эту архитектуру. Docker-контейнер с одним H100 80GB.
Результат: 35 часов непрерывной работы, 1158 tool calls, 432 kernel evaluations, 5 архитектурных редизайнов — и итоговое ускорение 10.0× geometric mean.
Для сравнения: GLM 5.1 на той же задаче дала 7.3×, Kimi K2.6 — 5.0×, DeepSeek V4 Pro — 3.3×. Все остановились раньше.
Что здесь важно технически: модель не просто «писала код долго». Она сохраняла когерентную стратегию через тысячу вызовов инструментов на незнакомом железе, опираясь только на runtime feedback. Это называют long-horizon reasoning и in-context generalization.
Честная оговорка: тест self-reported, независимого воспроизведения пока нет. Ждём.
Максим: «Я перечитал этот фрагмент про 35 часов несколько раз. Мы с командой делаем агентные пайплайны GoBanana — и главная боль всегда была в том, что модели деградируют после 50-100 шагов. Если Qwen реально держит контекст через 1000+ tool calls, это меняет то, что вообще возможно автоматизировать.»
| Модель | Input | Output | Blended $/1M |
|---|---|---|---|
| Qwen3.7-Max | $2.50 | $7.50 | $10.00 |
| Gemini 3.5 Flash | — | — | $10.50 |
| GPT-5.4 | $2.50 | $15.00 | $17.50 |
| Claude Opus 4.7 | $15.00 | $75.00 | $30.00 |
| DeepSeek V4 Pro | — | — | $5.22 |
| GLM-5.1 | — | — | $5.80 |
Позиционирование чёткое: дороже китайских конкурентов (DeepSeek, GLM), но в 3 раза дешевле Claude Opus 4.7 при сопоставимом качестве на coding-задачах. Web Search через API — $10 за 1000 вызовов. Code Interpreter — бесплатно в ограниченный период.
Чат на chat.qwen.ai — бесплатно, с Thinking Mode.

Claude Code работает с моделями Qwen через Anthropic API-совместимый интерфейс Alibaba Cloud Model Studio — только международный режим, регион Сингапур.
export ANTHROPIC_BASE_URL=https://dashscope-intl.aliyuncs.com/apps/anthropic
export ANTHROPIC_API_KEY=YOUR_DASHSCOPE_API_KEY
export ANTHROPIC_MODEL=qwen3.7-max
claudeЭто не хак и не прокси. Qwen3.7-Max поддерживает Anthropic API протокол нативно, что позволяет подключать его напрямую к Claude Code или OpenClaw. Переменная ANTHROPIC_API_KEY здесь принимает ваш DashScope ключ — не ключ Anthropic. Название переменной совпадает, потому что Claude Code использует её как универсальную точку входа.
Для сохранения в профиль постоянно:
echo 'export ANTHROPIC_BASE_URL="https://dashscope-intl.aliyuncs.com/apps/anthropic"' >> ~/.zshrc
echo 'export ANTHROPIC_API_KEY="YOUR_DASHSCOPE_API_KEY"' >> ~/.zshrc
echo 'export ANTHROPIC_MODEL="qwen3.7-max"' >> ~/.zshrcЧерез Python API с Thinking Mode:
extra_body={"enable_thinking": True}Одно важное замечание: переменная ANTHROPIC_API_KEY здесь принимает ваш DashScope ключ, а не ключ Anthropic. Название вводит в заблуждение, но если у вас есть реальный ключ Anthropic под другим именем — конфликта не будет.

Thinking Mode / No-Think Mode — дуальный режим. Для сложных задач включать Thinking Mode, для простых — No-Think (экономит токены и снижает latency). Thinking budget настраивается: можно задать лимит токенов на рассуждение и найти оптимальный баланс скорость/качество под свою задачу.
Task-Harness-Verifier — тренировочный подход Alibaba. Ортогональная декомпозиция: задача, харнесс (окружение выполнения), верификатор результата разделены. Это позволяет тренировать модель на разнообразных окружениях без переобучения под конкретный фреймворк.
Self-Monitoring — встроенная система детекции reward hacking. Модель автономно добавила 13 эвристических правил и поймала 1618 случаев попыток «считерить» в процессе тренировки.
API-совместимость: OpenAI API и Anthropic API — оба нативно, без адаптеров.
Эндпоинты: Сингапур, Пекин, US Virginia. Данные хранятся в регионе эндпоинта — важно для команд с требованиями к дата-суверенитету.
Все предыдущие флагманы Qwen выходили с открытыми весами под Apache 2.0 — Qwen 2.5, 3.5, 3.6. Сообщество привыкло.
Qwen3.7-Max — проприетарный, API-only, веса закрыты. Alibaba делает то, что OpenAI и Anthropic делали с GPT-4 и Claude: флагман за API, младшие версии — open-source. Qwen3.7-Plus-Preview (мультимодальная версия уровнем ниже) обещают открыть.
Реакция на HN (582 очка, 233 комментария): «Ждём открытые веса, особенно 122B и 397B», «60-150B диапазон — sweet spot для prosumer-железа». Комьюнити расстроено, но уважает инженерные достижения.
Для практического использования это означает: нельзя запустить локально, нужно доверять Alibaba Cloud, зависимость от интернета для агентных воркфлоу.
Длинные автономные agent-воркфлоу — это главная суперсила. Если задача требует десятков или сотен шагов без вашего участия — первый выбор на рынке прямо сейчас.
Многошаговый дебаггинг — независимые тесты показали: модель находит дополнительные проблемы за пределами заявленного промпта. В 2 из 5 дебаггинг-задач нашла проблемы которые не просили искать.
Математика и сложный reasoning — Apex Math 44.5, GPQA Diamond 92.4. Разрыв с конкурентами на math-бенчмарках реальный.
Office автоматизация через MCP — SpreadSheetBench 87, MCP-Mark 60.8. Для обработки таблиц и офисных воркфлоу — одна из лучших на рынке.
Бюджетный аналог Claude Code — как запасной backend когда Anthropic-тир заканчивается или нужна экономия в 3×.

Knowledge recall / фактология — attempt rate 48%. Если вам нужна модель которая уверенно отвечает на вопросы типа «когда произошло X» или «кто сделал Y» — Claude или GPT надёжнее.
Креативное письмо — Decrypt прямо пишет: «writes efficiently, not expressively». Модель оптимизирована под выполнение задач, а не под качество прозы.
Vision-задачи — Qwen3.7-Max текстовая. Для работы с изображениями нужен Qwen3.7-Plus-Preview.
Короткие быстрые запросы — overhead Thinking Mode нецелесообразен. Для быстрых чатов проще и дешевле что-то другое.
На Alibaba Cloud Summit вышли три продукта одновременно:
Qwen3.7-Max — флагманская LLM.
Zhenwu M890 (真武M890) — AI-ускоритель от T-Head, собственный чип Alibaba.
Panjiu AL128 (磐久AL128) — rack-scale сервер: 128 ускорителей M890 в одной стойке.
Рекурсивность: модель оптимизировала программный стек для чипа M890 — на том самом 35-часовом прогоне. Тот же чип теперь запускает модель. Alibaba строит полный вертикальный стек: модель, чип, сервер.
| Дата | Релиз |
|---|---|
| Март 2026 | Qwen3.5-Max-Preview |
| Апрель 2026 | Qwen3.6-Max-Preview |
| Май 2026 | Qwen3.7-Max |
Месячный цикл выдерживается точно. По этой логике — июньский релиз Qwen3.8 или следующий preview уже в разработке.
SWE-bench Verified — бенчмарк на решение реальных GitHub Issues. Измеряет способность агента самостоятельно фиксить баги в production-кодовых базах.
SWE-bench Pro — усложнённая версия SWE-bench, задачи с более высоким порогом сложности.
GPQA Diamond — Graduate-Level Google-Proof Q&A. Вопросы уровня PhD, которые не гуглятся. Один из лучших измерителей глубокого reasoning.
Apex Math — бенчмарк соревновательной математики. Задачи олимпийского уровня.
MCP-Mark / MCP-Atlas — бенчмарки агентной работы с MCP-инструментами. Измеряют как модель планирует и выполняет многошаговые задачи через внешние инструменты.
Thinking Mode — режим работы модели где часть токенов тратится на внутренние рассуждения перед ответом. Улучшает качество на сложных задачах за счёт скорости и стоимости.
Cross-harness generalization — способность агентной модели работать одинаково хорошо в разных фреймворках выполнения, без привязки к конкретной среде.
DashScope — API-платформа Alibaba Cloud для доступа к моделям Qwen. Международный эндпоинт: dashscope-intl.aliyuncs.com.
Qwen3.7-Max бесплатный?
Чат на chat.qwen.ai — бесплатно с Thinking Mode. API через Alibaba Cloud Model Studio платный: $2.50 input / $7.50 output за 1M токенов.
Можно ли запустить Qwen3.7-Max локально?
Нет. Это проприетарная модель API-only, веса закрыты. Для локального запуска есть более ранние открытые версии Qwen (27B, 35B-A3B под Apache 2.0).
Как подключить к Claude Code?
Три переменные окружения: ANTHROPIC_BASE_URL, ANTHROPIC_API_KEY (ваш DashScope ключ), ANTHROPIC_MODEL=qwen3.7-max. Подробно — в разделе выше.
Qwen3.7-Max лучше Claude Opus 4.7?
Зависит от задачи. На agent-воркфлоу и математике — часто лучше или паритет. На knowledge recall, качестве кода и agentic-понимании — Claude Opus 4.7 надёжнее. При этом Qwen стоит в 3 раза дешевле.
Где данные хранятся при использовании API?
В регионе эндпоинта: Сингапур, Пекин или US Virginia. Выбирайте регион в зависимости от требований к дата-суверенитету.
Когда выйдет следующая версия?
Alibaba держит месячный цикл: Qwen3.5 в марте, 3.6 в апреле, 3.7 в мае. Следующий релиз — вероятно, июнь 2026.
Qwen3.7-Plus-Preview — это то же самое?
Нет. Plus-Preview — мультимодальная версия уровнем ниже, с поддержкой изображений. Max — текстовый reasoning-флагман без vision.
Посмотреть все AI-инструменты и модели в одном месте — каталог AI-инструментов. Разобраться какая модель подходит под ваши задачи и как выстроить агентный стек — запишитесь на консультацию к Максиму.
Опубликовано: 22 мая 2026. Источники: официальный блог Qwen Team, VentureBeat, MarkTechPost, Decrypt, BenchLM.ai, Artificial Analysis, Medium @inprogrammer, Alibaba Cloud документация.